**/mall-member/sso/login**
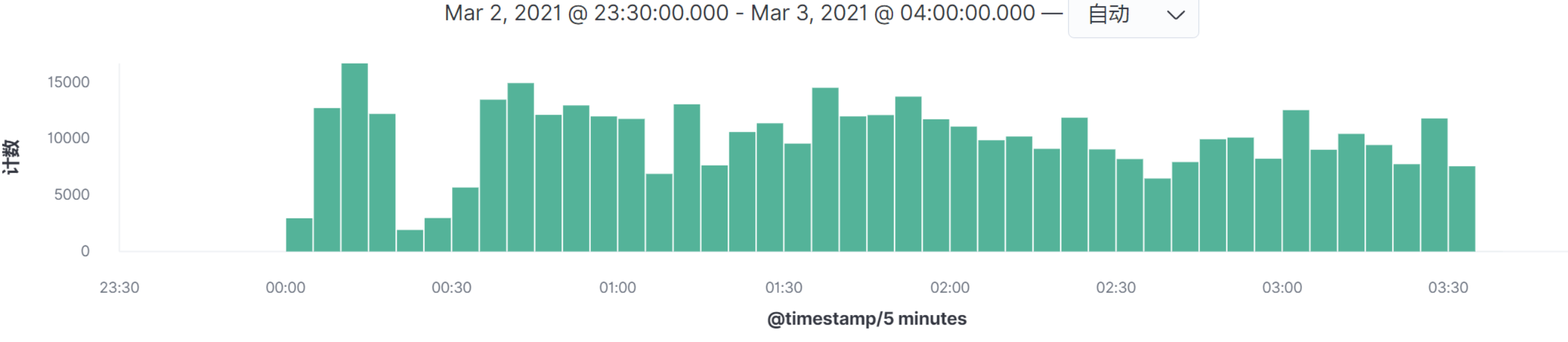
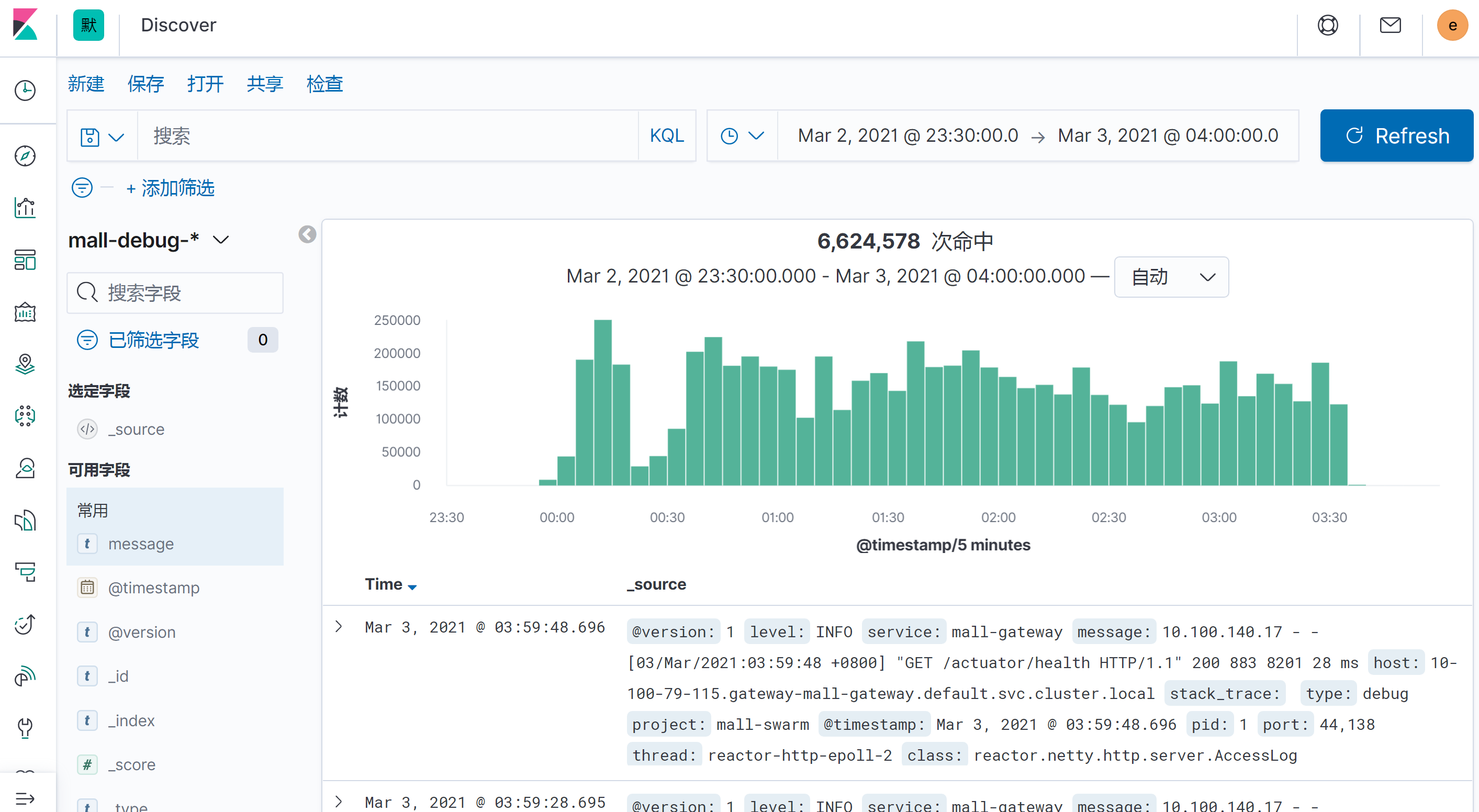 如上图所示,我们在Kibana中截取了一段时间的日志,这段日志总共有6,624,578次请求。你可以用Kibana直接生成下面这样的表格视图:
如上图所示,我们在Kibana中截取了一段时间的日志,这段日志总共有6,624,578次请求。你可以用Kibana直接生成下面这样的表格视图:
 这样你就可以知道哪些请求比较靠前。为什么我没有显示总数呢?因为在一段时间之内的每个请求,我们要生成相应的柱状图,如果看到它们的集中时间段是相同的,那就做一个场景即可;如果不同,则要做多个场景。下面我们来搜索一下。
这样你就可以知道哪些请求比较靠前。为什么我没有显示总数呢?因为在一段时间之内的每个请求,我们要生成相应的柱状图,如果看到它们的集中时间段是相同的,那就做一个场景即可;如果不同,则要做多个场景。下面我们来搜索一下。
**/mall-member/sso/login**
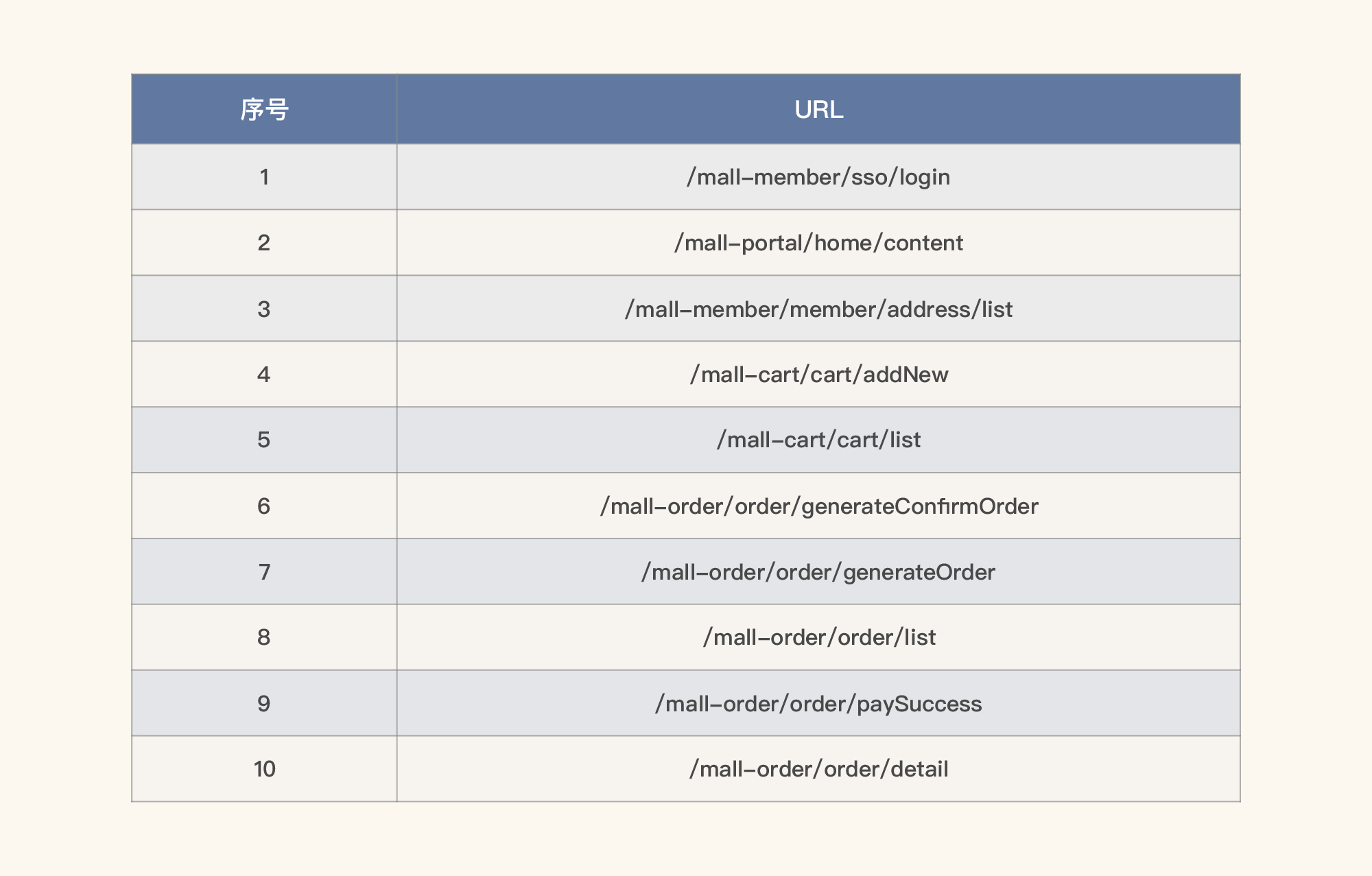
 - **/mall-member/member/address/list**
- **/mall-member/member/address/list**
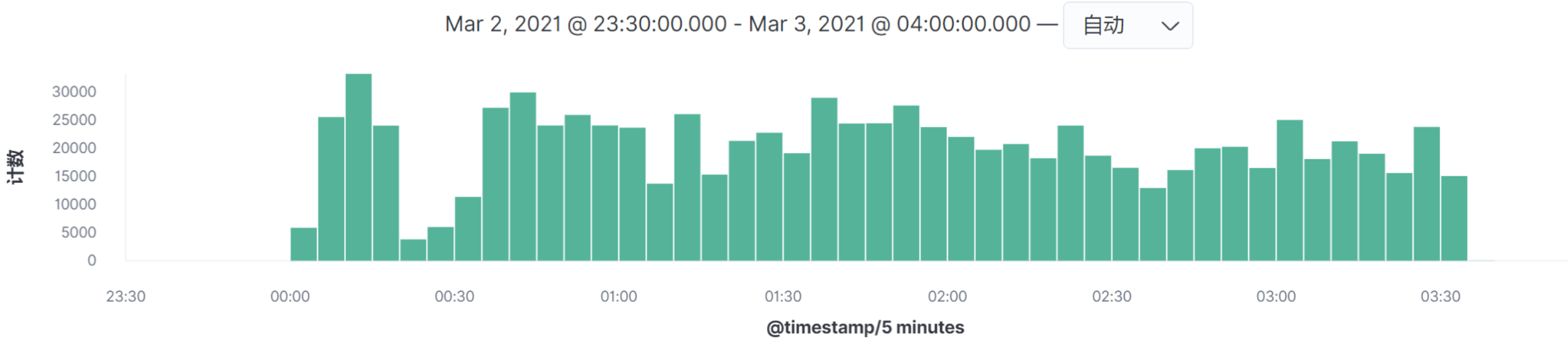 其他接口的图类似,我就不一一列了。
看图上的数据时间点,在我这个例子中,所有的请求量级的时间点都是相同的,所以我们只需要做一个场景即可全部覆盖。请你务必要注意,在你的实际项目中,并不见得会是这样。**如果出现某个请求的高并发时间点和其他的请求不在同一时间点,就一定要做多个场景来模拟,因为场景中的业务模型会发生变化。**
在我这个示例中,我们把数据量也列在表格中,同时求出比例关系,也就是拿某请求的数量除以总请求数,如下所示:
其他接口的图类似,我就不一一列了。
看图上的数据时间点,在我这个例子中,所有的请求量级的时间点都是相同的,所以我们只需要做一个场景即可全部覆盖。请你务必要注意,在你的实际项目中,并不见得会是这样。**如果出现某个请求的高并发时间点和其他的请求不在同一时间点,就一定要做多个场景来模拟,因为场景中的业务模型会发生变化。**
在我这个示例中,我们把数据量也列在表格中,同时求出比例关系,也就是拿某请求的数量除以总请求数,如下所示:
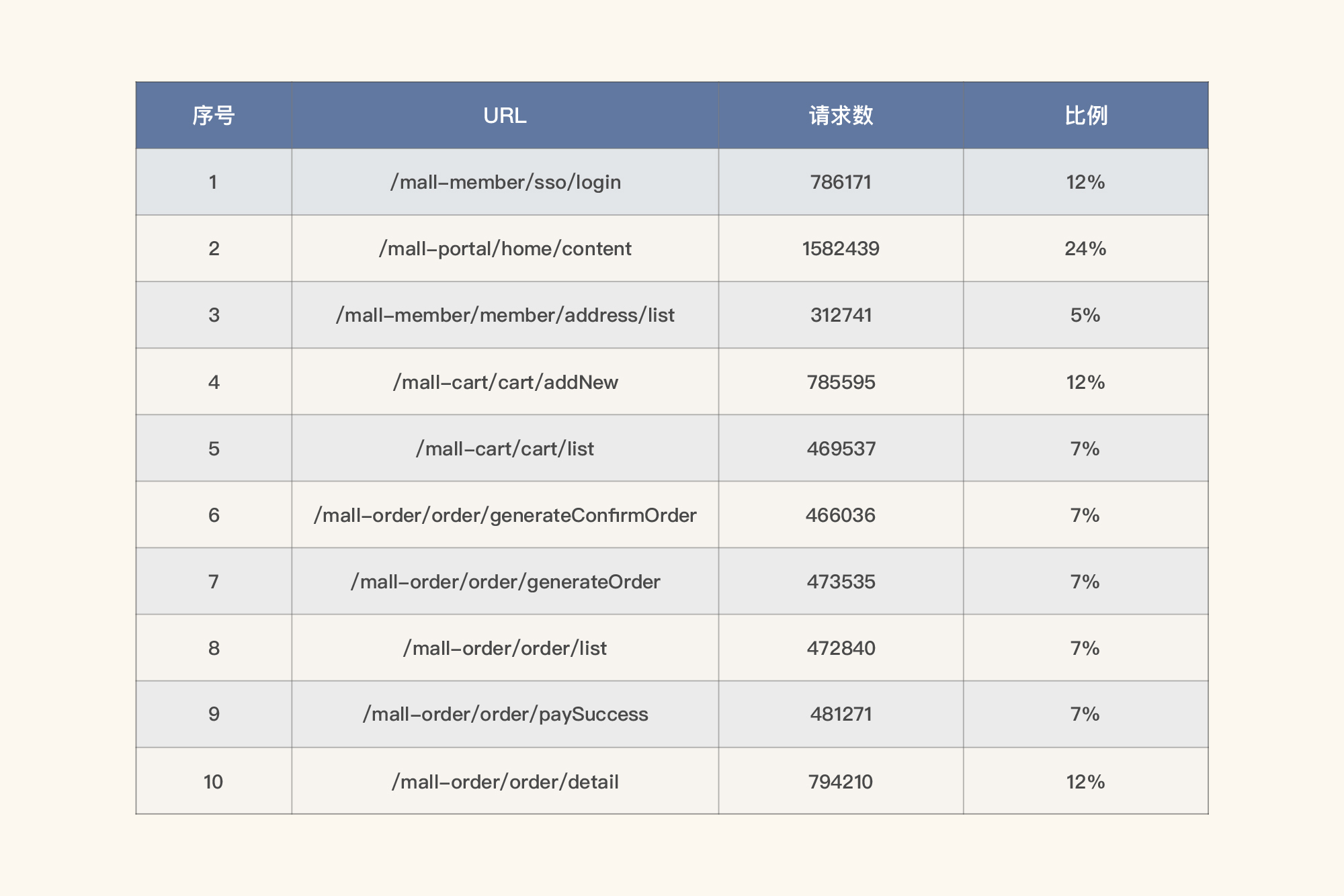 这是在这一个时间段的业务平均比例。
通过第一阶段,我们已经可以知道哪个时间段的请求高了。但是这个时间段范围是5分钟,这对于任何一个系统来说,都算是比较集中的时间段了。但是我们的动作还没有结束,因为我们不仅要知道哪一段的用户操作比较集中,还要知道的是生产上能达到的TPS有多高。所以还需要细化,只有细化了我们才能知道具体生产的TPS。
### 第二个阶段:细化时间段
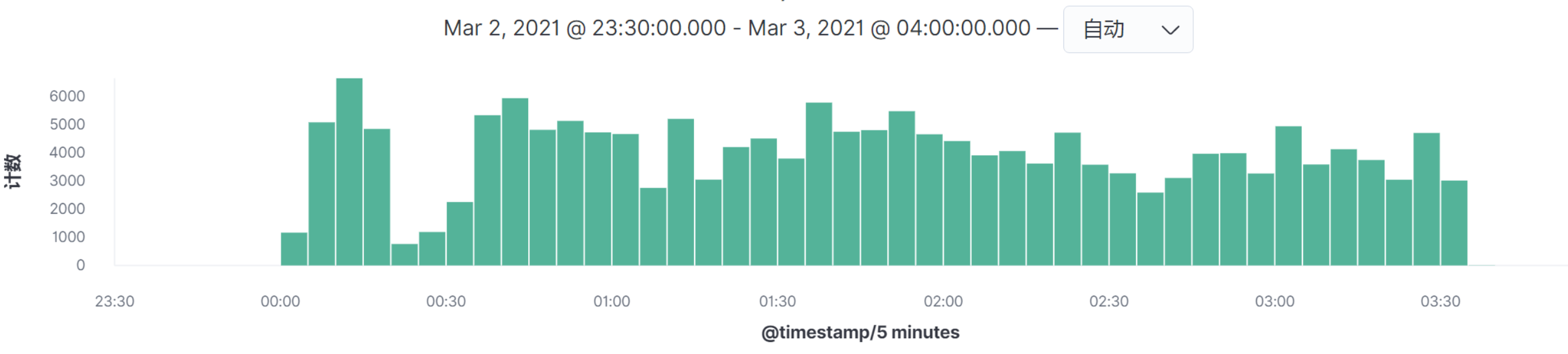
通过主面图中的Timestamp,可以看到是时间间隔是5分钟,我们选择最高请求的时间段,点进去。
这是在这一个时间段的业务平均比例。
通过第一阶段,我们已经可以知道哪个时间段的请求高了。但是这个时间段范围是5分钟,这对于任何一个系统来说,都算是比较集中的时间段了。但是我们的动作还没有结束,因为我们不仅要知道哪一段的用户操作比较集中,还要知道的是生产上能达到的TPS有多高。所以还需要细化,只有细化了我们才能知道具体生产的TPS。
### 第二个阶段:细化时间段
通过主面图中的Timestamp,可以看到是时间间隔是5分钟,我们选择最高请求的时间段,点进去。
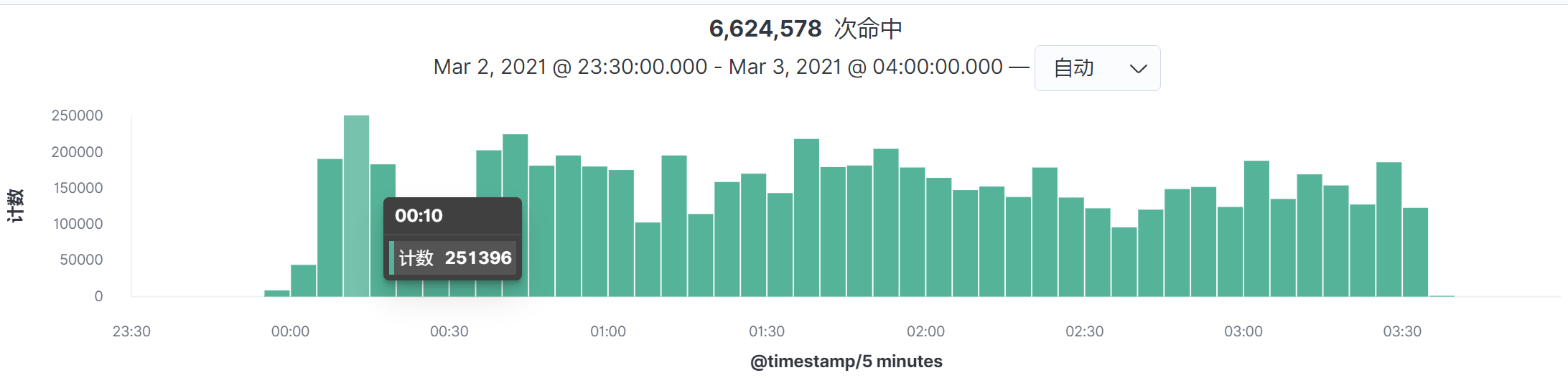 这样我们就得到时间间隔为5秒的图了:
这样我们就得到时间间隔为5秒的图了:
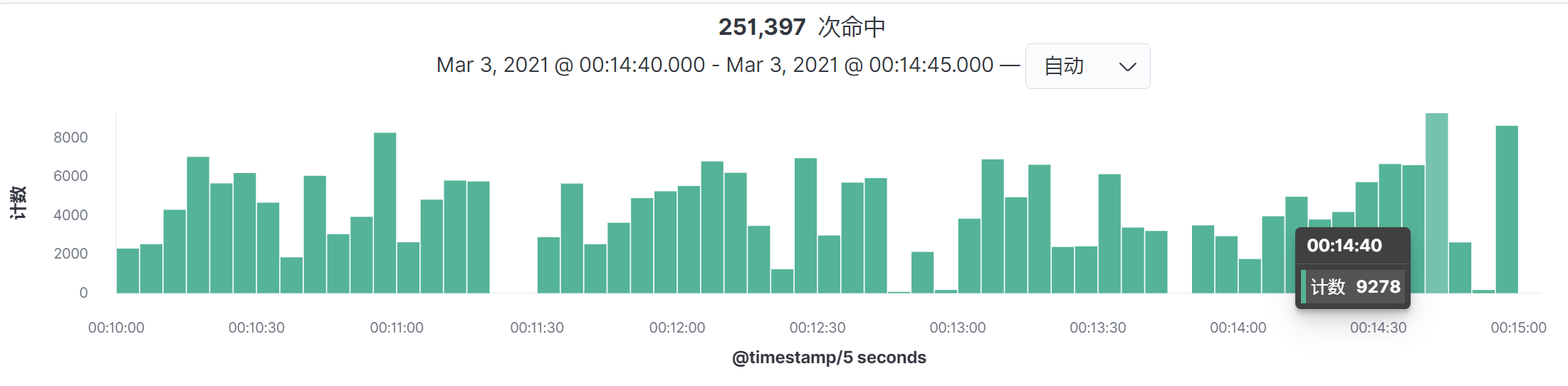 然后按命中次数来计算TPS,就可以得到如下结果:
$生产TPS = 9278 \div 5 = 1,855.6$
当然了,你还可以再细化,得到毫秒级的图:
然后按命中次数来计算TPS,就可以得到如下结果:
$生产TPS = 9278 \div 5 = 1,855.6$
当然了,你还可以再细化,得到毫秒级的图:
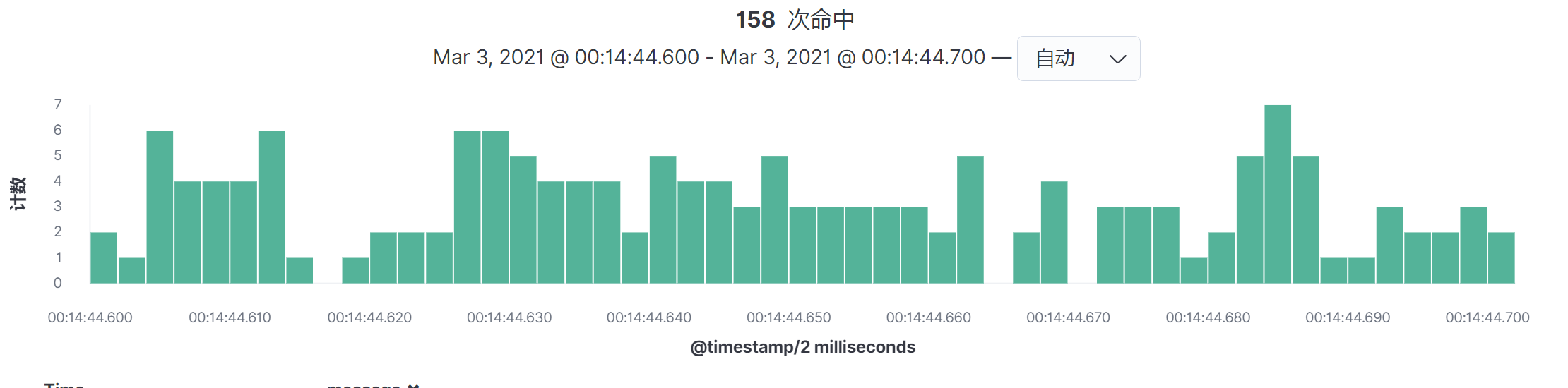 通过这种方式,我们就可以得知一个系统在生产环境中的峰值的TPS有多大。1855.6这个值是我们要定的测试环境中总的TPS。如果达不到这个值,那就要接着优化,或者增加硬件资源。
通常情况下,得到总TPS之后,我们要根据测试目标,分三种方式处理这个总TPS,而这三种方式都是以**业务目标**为前提的。
1. **业务无变化,应用版本有小变化**(通常只是小的功能变化或修改Bug):在这种情况下,我们只要将计算出来的TPS做为性能场景总的TPS指标即可。
1. **业务无变化,应用版本有大变化**(比如说架构变更):在这种情况下,我们只要将计算出来的TPS做为性能场景总的TPS指标即可。
1. **业务有变化,应用版本有大变化**:在这种情况下,我们要根据业务估算的增量来做相应的TPS增量计算。如果根据业务变化趋势预估会增加20%,那你就可以在上面计算的总TPS的基础上,再加上对应的20%即可。
## 梳理业务逻辑
在上面的接口得到业务模型之后,我们就可以根据接口的量级梳理业务逻辑,以便更真实地模拟生产业务场景。其实在上面的步骤中,我们已经按顺序做了排列,你可以看一下前面的表格。
所以在这个示例中,大概有58%的用户会完整地走完流程。为什么是58%呢?因为登录的业务比例是12%,而后面下单比例是7%。所以是:
通过这种方式,我们就可以得知一个系统在生产环境中的峰值的TPS有多大。1855.6这个值是我们要定的测试环境中总的TPS。如果达不到这个值,那就要接着优化,或者增加硬件资源。
通常情况下,得到总TPS之后,我们要根据测试目标,分三种方式处理这个总TPS,而这三种方式都是以**业务目标**为前提的。
1. **业务无变化,应用版本有小变化**(通常只是小的功能变化或修改Bug):在这种情况下,我们只要将计算出来的TPS做为性能场景总的TPS指标即可。
1. **业务无变化,应用版本有大变化**(比如说架构变更):在这种情况下,我们只要将计算出来的TPS做为性能场景总的TPS指标即可。
1. **业务有变化,应用版本有大变化**:在这种情况下,我们要根据业务估算的增量来做相应的TPS增量计算。如果根据业务变化趋势预估会增加20%,那你就可以在上面计算的总TPS的基础上,再加上对应的20%即可。
## 梳理业务逻辑
在上面的接口得到业务模型之后,我们就可以根据接口的量级梳理业务逻辑,以便更真实地模拟生产业务场景。其实在上面的步骤中,我们已经按顺序做了排列,你可以看一下前面的表格。
所以在这个示例中,大概有58%的用户会完整地走完流程。为什么是58%呢?因为登录的业务比例是12%,而后面下单比例是7%。所以是: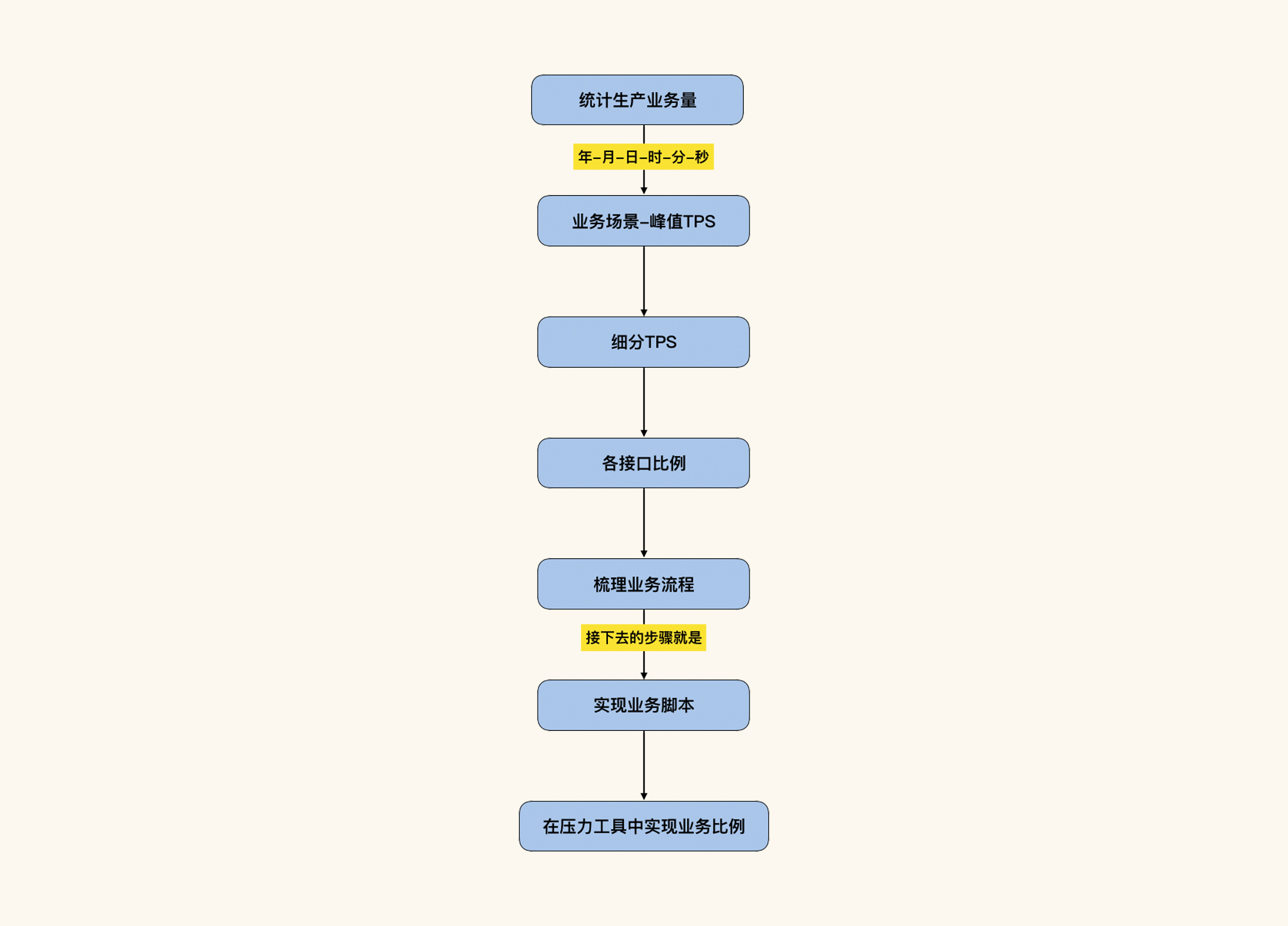 请注意,上面的业务场景在实际的项目业务统计过程中可以有多个。这个思路可以解决任何性能场景和生产场景不一致的问题。
## 总结
最后,我们再一起回顾下这一讲的重点内容。在业务模型抽取时我们要注意几个关键点:
1. 抽取时间:抽取时间一定要能覆盖生产系统的峰值时间点;
1. 抽取范围:抽取的范围要足够大,因为在一些场景中,即便不是峰值,但由于某个业务量较大,也会出现资源消耗大的情况;
1. 业务比例在场景中的实现:得到业务模型之后,我们在性能场景中一定要配置出对应的业务比例,不能有大的偏差。
只要做到以上几点,性能场景基本上就不会和真实业务场景有大的差异了。
## 课后作业
学完这节课后,请你认真思考两个问题:
1. 为什么性能场景中要模拟出真实业务比例?
1. 抽取生产数据并最终得到业务模型的步骤是什么?
欢迎你在留言区与我交流讨论。当然了,你也可以把这节课分享给你身边的朋友,他们的一些想法或许会让你有更大的收获。我们下节课见!
**关于课程读者群**
点击课程详情页的链接,扫描二维码,就可以加入我们这个课程的读者群哦,希望这里的交流与思维碰撞能帮助你取得更大的进步,期待你的到来~
请注意,上面的业务场景在实际的项目业务统计过程中可以有多个。这个思路可以解决任何性能场景和生产场景不一致的问题。
## 总结
最后,我们再一起回顾下这一讲的重点内容。在业务模型抽取时我们要注意几个关键点:
1. 抽取时间:抽取时间一定要能覆盖生产系统的峰值时间点;
1. 抽取范围:抽取的范围要足够大,因为在一些场景中,即便不是峰值,但由于某个业务量较大,也会出现资源消耗大的情况;
1. 业务比例在场景中的实现:得到业务模型之后,我们在性能场景中一定要配置出对应的业务比例,不能有大的偏差。
只要做到以上几点,性能场景基本上就不会和真实业务场景有大的差异了。
## 课后作业
学完这节课后,请你认真思考两个问题:
1. 为什么性能场景中要模拟出真实业务比例?
1. 抽取生产数据并最终得到业务模型的步骤是什么?
欢迎你在留言区与我交流讨论。当然了,你也可以把这节课分享给你身边的朋友,他们的一些想法或许会让你有更大的收获。我们下节课见!
**关于课程读者群**
点击课程详情页的链接,扫描二维码,就可以加入我们这个课程的读者群哦,希望这里的交流与思维碰撞能帮助你取得更大的进步,期待你的到来~