前段时间,我写了一系列分布式系统架构方面的文章,有很多读者纷纷留言讨论相关的话题,还有读者留言表示对分布式系统架构这个主题感兴趣,希望我能推荐一些学习资料。
就像我在前面的文章中多次提到的,分布式系统的技术栈巨大无比,所以我要推荐的学习资料也比较多,后面在文章中我会结合主题逐步推荐给你。在今天这篇文章中,我将推荐一些分布式系统的基础理论和一些不错的图书和资料。
这篇文章比较长,所以我特意整理了目录,帮你快速找到自己感兴趣的内容。
# 基础理论
- CAP 定理
- Fallacies of Distributed Computing
# 经典资料
- Distributed systems theory for the distributed systems engineer
- FLP Impossibility Result
- An introduction to distributed systems
- Distributed Systems for fun and profit
- Distributed Systems: Principles and Paradigms
- Scalable Web Architecture and Distributed Systems
- Principles of Distributed Systems
- Making reliable distributed systems in the presence of software errors
- Designing Data Intensive Applications
# 基础理论
下面这些基础知识有可能你已经知道了,不过还是容我把它分享在这里。我希望用比较通俗易懂的文字将这些枯燥的理论知识讲请楚。
## [CAP定理](https://en.wikipedia.org/wiki/CAP_theorem)
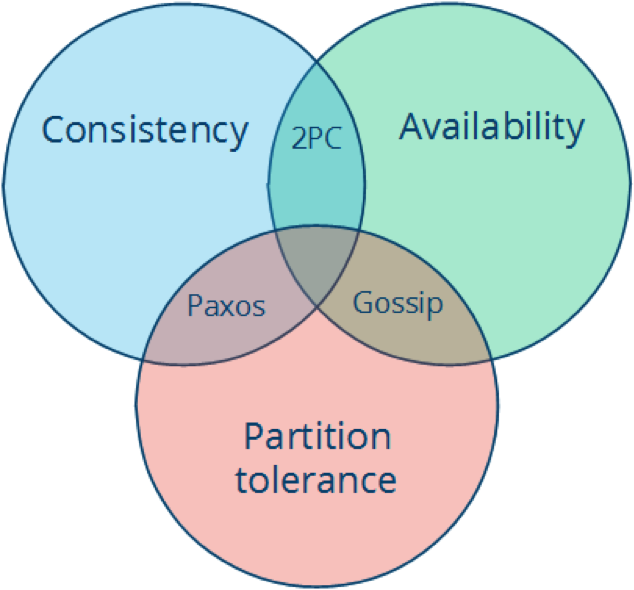
CAP定理是分布式系统设计中最基础,也是最为关键的理论。它指出,分布式数据存储不可能同时满足以下三个条件。
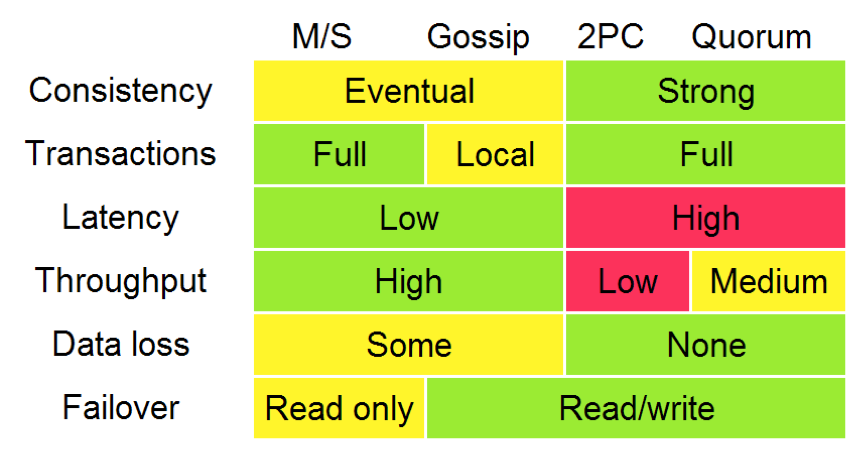
CA (consistency + availability),这样的系统关注一致性和可用性,它需要非常严格的全体一致的协议,比如“两阶段提交”(2PC)。CA系统不能容忍网络错误或节点错误,一旦出现这样的问题,整个系统就会拒绝写请求,因为它并不知道对面的那个结点是否挂掉了,还是只是网络问题。唯一安全的做法就是把自己变成只读的。
AP (availability + partition tolerance),这样的系统关心可用性和分区容忍性。因此,这样的系统不能达成一致性,需要给出数据冲突,给出数据冲突就需要维护数据版本。Dynamo就是这样的系统。
然而,还是有一些人会错误地理解CAP定理,甚至误用。Cloudera工程博客中,[CAP Confusion: Problems with ‘partition tolerance’](http://blog.cloudera.com/blog/2010/04/cap-confusion-problems-with-partition-tolerance/)一文中对此有详细的阐述。
在谷歌的[Transaction Across DataCenter视频](http://www.youtube.com/watch?v=srOgpXECblk)中,我们可以看到下面这样的图。这个是CAP理论在具体工程中的体现。
## [Fallacies of Distributed Computing](http://en.wikipedia.org/wiki/Fallacies_of_distributed_computing)
本文是英文维基百科上的一篇文章。它是Sun公司的[劳伦斯·彼得·多伊奇(Laurence Peter Deutsch)](https://en.wikipedia.org/wiki/L_Peter_Deutsch)等人于1994~1997年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于1946年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的Ghostscript开源软件,于1988年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了Smalltalk,并且他的开发成果激发了后来Java语言JIT编译技术的创造灵感。他后来在Sun公司工作并成为Sun的公司院士。在1994年,他成为了ACM院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下8条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
1. 网络是稳定的。
1. 网络传输的延迟是零。
1. 网络的带宽是无穷大。
1. 网络是安全的。
1. 网络的拓扑不会改变。
1. 只有一个系统管理员。
1. 传输数据的成本为零。
1. 整个网络是同构的。
阿尔农·罗特姆-盖尔-奥兹(Arnon Rotem-Gal-Oz)写了一篇长文[Fallacies of Distributed Computing Explained](http://www.rgoarchitects.com/Files/fallacies.pdf)来解释这些点。
由于他写这篇文章的时候已经是2006年了,所以从中能看到这8条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了AJAX,而这是2005年开始流行的技术。
而[加勒思·威尔逊(Gareth Wilson)的文章](http://blog.fogcreek.com/eight-fallacies-of-distributed-computing-tech-talk/)则用日常生活中的例子,对这些点做了更为通俗的解释。
这8个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这8点则是应用程序开发者也必须知道的。
**为什么我们要深刻地认识这8个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。**
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
# 经典资料
## [Distributed systems theory for the distributed systems engineer](http://the-paper-trail.org/blog/distributed-systems-theory-for-the-distributed-systems-engineer/)
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正的领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了4份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
[Distributed Systems for Fun and Profit](http://book.mixu.net/distsys/),这是一本小书,涵盖了分布式系统中的关键问题,包括时间的作用和不同的复制策略。后文中对这本书有较详细的介绍。
[Notes on distributed systems for young bloods](https://www.somethingsimilar.com/2013/01/14/notes-on-distributed-systems-for-young-bloods/),这篇文章中没有理论,是一份适合新手阅读的分布式系统实践笔记。
[A Note on Distributed Systems](http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.41.7628),这是一篇经典的论文,讲述了为什么在分布式系统中,远程交互不能像本地对象那样进行。
[The fallacies of distributed computing](https://en.wikipedia.org/wiki/Fallacies_of_distributed_computing),每个分布式系统新手都会做的8个错误假设,并探讨了其会带来的影响。上文中专门对这篇文章做了介绍。
随后,分享了几个关键点。
- **失败和时间(Failure and Time)**。分布式系统工程师面临的很多困难都可以归咎于两个根本原因:1. 进程可能会失败;2. 没有好方法表明进程失败。这就涉及到如何设置系统时钟,以及进程间的通讯机制,在没有任何共享时钟的情况下,如何确定一个事件发生在另一个事件之前。
可以参考Lamport时钟和Vector时钟,还可以看看[Dynamo论文](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)。
- **容错的压力(The basic tension of fault tolerance)**。能在不降级的情况下容错的系统一定要像没有错误发生的那样运行。这就意味着,系统的某些部分必须冗余地工作,从而在性能和资源消耗两方面带来成本。
最终一致性以及其他技术方案在以系统行为弱保证为代价,来试图避免这种系统压力。阅读[Dynamo论文](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)和帕特·赫尔兰(Pat Helland)的经典论文[Life Beyond Transactions](http://www.cloudtran.com/pdfs/LifeBeyondDistTRX.pdf)能获很得大启发。
 ## [Fallacies of Distributed Computing](http://en.wikipedia.org/wiki/Fallacies_of_distributed_computing)
本文是英文维基百科上的一篇文章。它是Sun公司的[劳伦斯·彼得·多伊奇(Laurence Peter Deutsch)](https://en.wikipedia.org/wiki/L_Peter_Deutsch)等人于1994~1997年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于1946年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的Ghostscript开源软件,于1988年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了Smalltalk,并且他的开发成果激发了后来Java语言JIT编译技术的创造灵感。他后来在Sun公司工作并成为Sun的公司院士。在1994年,他成为了ACM院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下8条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
1. 网络是稳定的。
1. 网络传输的延迟是零。
1. 网络的带宽是无穷大。
1. 网络是安全的。
1. 网络的拓扑不会改变。
1. 只有一个系统管理员。
1. 传输数据的成本为零。
1. 整个网络是同构的。
阿尔农·罗特姆-盖尔-奥兹(Arnon Rotem-Gal-Oz)写了一篇长文[Fallacies of Distributed Computing Explained](http://www.rgoarchitects.com/Files/fallacies.pdf)来解释这些点。
由于他写这篇文章的时候已经是2006年了,所以从中能看到这8条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了AJAX,而这是2005年开始流行的技术。
而[加勒思·威尔逊(Gareth Wilson)的文章](http://blog.fogcreek.com/eight-fallacies-of-distributed-computing-tech-talk/)则用日常生活中的例子,对这些点做了更为通俗的解释。
这8个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这8点则是应用程序开发者也必须知道的。
**为什么我们要深刻地认识这8个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。**
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
# 经典资料
## [Distributed systems theory for the distributed systems engineer](http://the-paper-trail.org/blog/distributed-systems-theory-for-the-distributed-systems-engineer/)
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正的领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了4份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
## [Fallacies of Distributed Computing](http://en.wikipedia.org/wiki/Fallacies_of_distributed_computing)
本文是英文维基百科上的一篇文章。它是Sun公司的[劳伦斯·彼得·多伊奇(Laurence Peter Deutsch)](https://en.wikipedia.org/wiki/L_Peter_Deutsch)等人于1994~1997年提出的,讲的是刚刚进入分布式计算领域的程序员常会有的一系列错误假设。
多伊奇于1946年出生在美国波士顿。他创办了阿拉丁企业(Aladdin Enterprises),并在该公司编写出了著名的Ghostscript开源软件,于1988年首次发布。
他在学生时代就和艾伦·凯(Alan Kay)等比他年长的人一起开发了Smalltalk,并且他的开发成果激发了后来Java语言JIT编译技术的创造灵感。他后来在Sun公司工作并成为Sun的公司院士。在1994年,他成为了ACM院士。
基本上,每个人刚开始建立一个分布式系统时,都做了以下8条假定。随着时间的推移,每一条都会被证明是错误的,也都会导致严重的问题,以及痛苦的学习体验。
1. 网络是稳定的。
1. 网络传输的延迟是零。
1. 网络的带宽是无穷大。
1. 网络是安全的。
1. 网络的拓扑不会改变。
1. 只有一个系统管理员。
1. 传输数据的成本为零。
1. 整个网络是同构的。
阿尔农·罗特姆-盖尔-奥兹(Arnon Rotem-Gal-Oz)写了一篇长文[Fallacies of Distributed Computing Explained](http://www.rgoarchitects.com/Files/fallacies.pdf)来解释这些点。
由于他写这篇文章的时候已经是2006年了,所以从中能看到这8条常见错误被提出十多年后还有什么样的影响:一是,为什么当今的分布式软件系统也需要避免这些设计错误;二是,在当今的软硬件环境里,这些错误意味着什么。比如,文中在谈“延迟为零”假设时,还谈到了AJAX,而这是2005年开始流行的技术。
而[加勒思·威尔逊(Gareth Wilson)的文章](http://blog.fogcreek.com/eight-fallacies-of-distributed-computing-tech-talk/)则用日常生活中的例子,对这些点做了更为通俗的解释。
这8个需要避免的错误不仅对于中间件和底层系统开发者及架构师是重要的知识,而且对于网络应用程序开发者也同样重要。分布式系统的其他部分,如容错、备份、分片、微服务等也许可以对应用程序开发者部分透明,但这8点则是应用程序开发者也必须知道的。
**为什么我们要深刻地认识这8个错误?是因为,这要我们清楚地认识到——在分布式系统中错误是不可能避免的,我们能做的不是避免错误,而是要把错误的处理当成功能写在代码中。**
后面,我会写一个系列的文章来谈一谈,分布式系统容错设计中的一些常见设计模式。敬请关注!
# 经典资料
## [Distributed systems theory for the distributed systems engineer](http://the-paper-trail.org/blog/distributed-systems-theory-for-the-distributed-systems-engineer/)
本文作者认为,推荐大量的理论论文是学习分布式系统理论的错误方法,除非这是你的博士课程。因为论文通常难度大又很复杂,需要认真学习,而且需要理解这些研究成果产生的时代背景,才能真正的领悟到其中的精妙之处。
在本文中,作者给出了他整理的分布式工程师必须要掌握的知识列表,并直言掌握这些足够设计出新的分布式系统。首先,作者推荐了4份阅读材料,它们共同概括了构建分布式系统的难点,以及所有工程师必须克服的技术难题。
