华盛顿大学教授、《终极算法》(The Master Algorithm)的作者佩德罗·多明戈斯曾在Communications of The ACM第55卷第10期上发表了一篇名为《机器学习你不得不知的那些事》(A Few Useful Things to Know about Machine Learning)的小文,介绍了12条机器学习中的“金科玉律”,其中的7/8两条说的就是对数据的作用的认识。
**多明戈斯的观点是:数据量比算法更重要**。即使算法本身并没有什么精巧的设计,但使用大量数据进行训练也能起到填鸭的效果,获得比用少量数据训练出来的聪明算法更好的性能。这也应了那句老话:**数据决定了机器学习的上限,而算法只是尽可能逼近这个上限**。
但多明戈斯嘴里的数据可不是硬件采集或者软件抓取的原始数据,而是经过特征工程处理之后的精修数据,**在他看来,特征工程(feature engineering)才是机器学习的关键**。通常来说,原始数据并不直接适用于学习,而是特征筛选、构造和生成的基础。一个好的预测模型与高效的特征提取和明确的特征表示息息相关,如果通过特征工程得到很多独立的且与所属类别相关的特征,那学习过程就变成小菜一碟。
**特征的本质是用于预测分类结果的信息,特征工程实际上就是对这些信息的编码。**机器学习中的很多具体算法都可以归纳到特征工程的范畴之中,比如使用$L_1$正则化项的**LASSO回归**,就是通过将某些特征的权重系数缩小到0来实现特征的过滤;再比如**主成分分析**,将具有相关性的一组特征变换为另一组线性无关的特征。这些方法本质上完成的都是特征工程的任务。
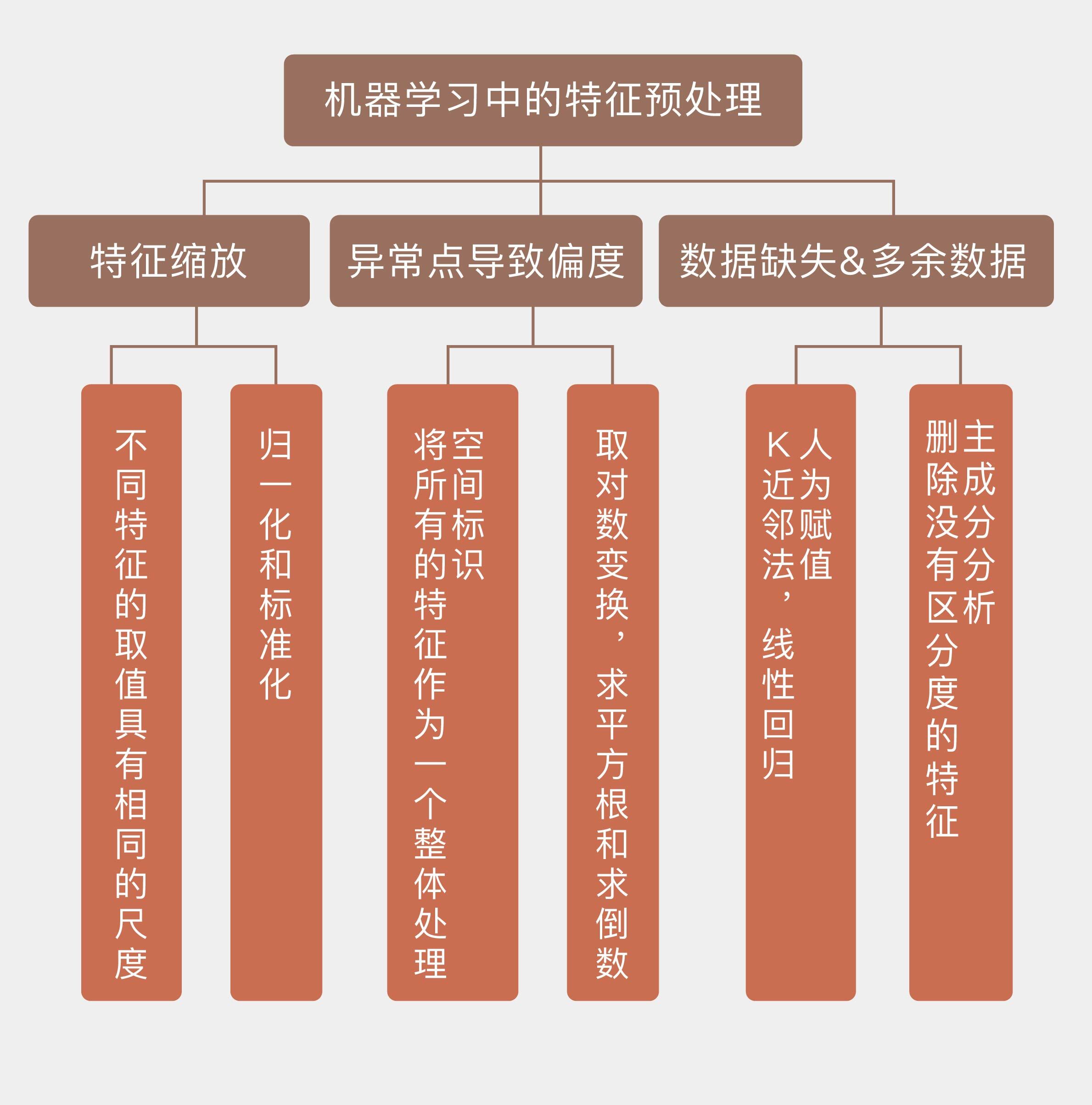
但是今天,我将不会讨论这些,而是把关注点放在算法之外,看一看**在特征工程之前,数据的特征需要经过哪些必要的预处理(preprocessing)**。
**特征缩放**(feature scaling)可能是最广为人知的预处理技巧了,它的目的是**保证所有的特征数值具有相同的数量级**。在有些情况下,数据中的某些特征会具有不同的尺度,比如在电商上买衣服时,身高和体重就是不同尺度的特征。
假设我的身高/体重是1.85米/64公斤,而买了同款衣服的两个朋友,1.75米/80公斤的穿L号合适,1.58米/52公斤的穿S号正好。直观判断的话,L码应该更合适我。可如果把(身高,体重)的二元组看作二维空间上的点的话,代表我自己的点显然和代表S码的点之间的欧式距离更近。如果电商不开眼的话,保不齐就会把S码推荐给我。
实际上,不会有电商做出这么弱智的推荐,因为他们都会进行特征缩放。在上面的例子中,由于体重数据比身高数据高出了一个数量级,因此在计算欧式距离时,身高的影响相比于体重是可以忽略不计的,起作用的相当于只有体重一个特征,这样的算法自然就会把体重相近的划分到同一个类别。
**特征缩放的作用就是消除特征的不同尺度所造成的偏差**,具体的变换方法有以下这两种: