# 配列
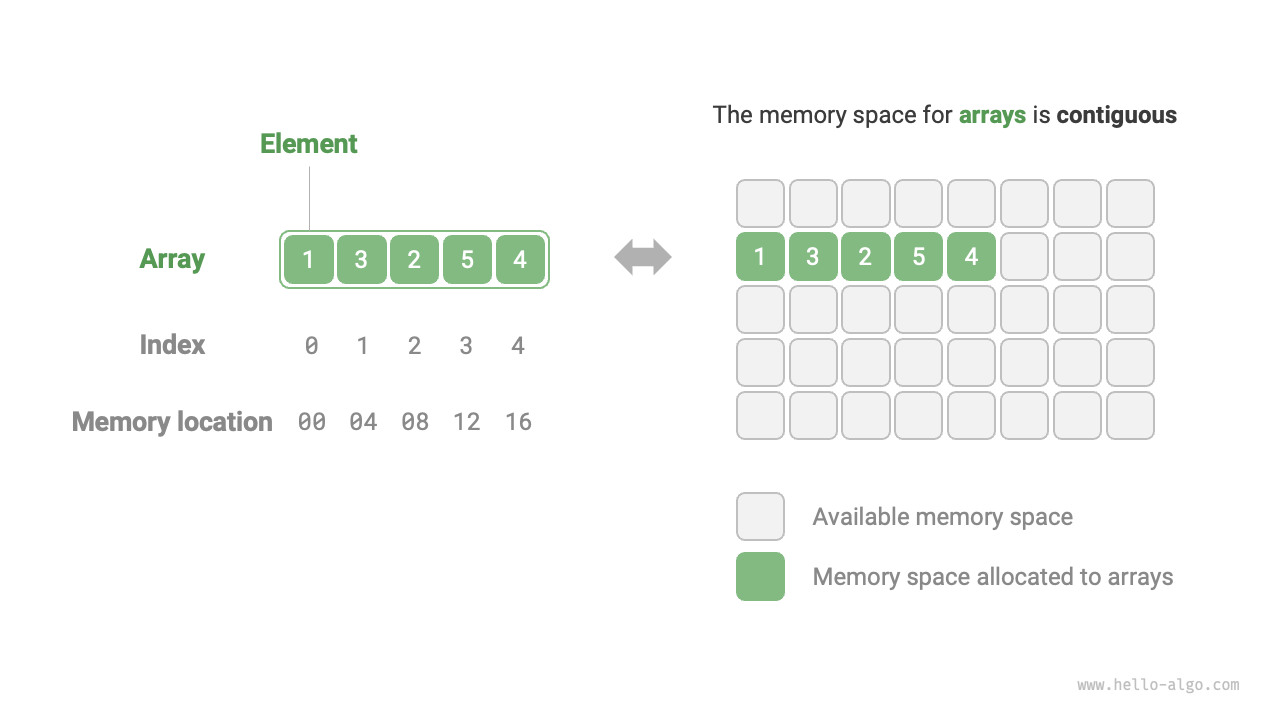
配列(array)は線形データ構造の一種であり、同じ型の要素を連続したメモリ領域に格納します。要素が配列内にある位置を、その要素のインデックス(index)と呼びます。下図は、配列の主要な概念と格納方式を示しています。
## 配列の一般的な操作
### 配列の初期化
必要に応じて、配列の初期化方法として初期値なしと初期値ありの 2 種類を使い分けられます。初期値を指定しない場合、多くのプログラミング言語では配列要素は $0$ に初期化されます。
=== "Python"
```python title="array.py"
# 配列を初期化する
arr: list[int] = [0] * 5 # [ 0, 0, 0, 0, 0 ]
nums: list[int] = [1, 3, 2, 5, 4]
```
=== "C++"
```cpp title="array.cpp"
/* 配列を初期化する */
// スタック上に格納
int arr[5];
int nums[5] = { 1, 3, 2, 5, 4 };
// ヒープ上に格納(手動で領域を解放する必要がある)
int* arr1 = new int[5];
int* nums1 = new int[5] { 1, 3, 2, 5, 4 };
```
=== "Java"
```java title="array.java"
/* 配列を初期化する */
int[] arr = new int[5]; // { 0, 0, 0, 0, 0 }
int[] nums = { 1, 3, 2, 5, 4 };
```
=== "C#"
```csharp title="array.cs"
/* 配列を初期化する */
int[] arr = new int[5]; // [ 0, 0, 0, 0, 0 ]
int[] nums = [1, 3, 2, 5, 4];
```
=== "Go"
```go title="array.go"
/* 配列を初期化する */
var arr [5]int
// Go では、長さを指定する場合([5]int)は配列であり、長さを指定しない場合([]int)はスライス
// Go の配列はコンパイル時に長さが確定するよう設計されているため、長さの指定には定数しか使用できない
// 拡張 extend() メソッドを実装しやすくするため、以下ではスライス(Slice)を配列(Array)として扱う
nums := []int{1, 3, 2, 5, 4}
```
=== "Swift"
```swift title="array.swift"
/* 配列を初期化する */
let arr = Array(repeating: 0, count: 5) // [0, 0, 0, 0, 0]
let nums = [1, 3, 2, 5, 4]
```
=== "JS"
```javascript title="array.js"
/* 配列を初期化する */
var arr = new Array(5).fill(0);
var nums = [1, 3, 2, 5, 4];
```
=== "TS"
```typescript title="array.ts"
/* 配列を初期化する */
let arr: number[] = new Array(5).fill(0);
let nums: number[] = [1, 3, 2, 5, 4];
```
=== "Dart"
```dart title="array.dart"
/* 配列を初期化する */
List arr = List.filled(5, 0); // [0, 0, 0, 0, 0]
List nums = [1, 3, 2, 5, 4];
```
=== "Rust"
```rust title="array.rs"
/* 配列を初期化する */
let arr: [i32; 5] = [0; 5]; // [0, 0, 0, 0, 0]
let slice: &[i32] = &[0; 5];
// Rust では、長さを指定する場合([i32; 5])は配列であり、長さを指定しない場合(&[i32])はスライス
// Rust の配列はコンパイル時に長さが確定するよう設計されているため、長さの指定には定数しか使用できない
// Vector は Rust で一般に動的配列として使われる型
// 拡張 extend() メソッドを実装しやすくするため、以下では vector を配列(array)として扱う
let nums: Vec = vec![1, 3, 2, 5, 4];
```
=== "C"
```c title="array.c"
/* 配列を初期化する */
int arr[5] = { 0 }; // { 0, 0, 0, 0, 0 }
int nums[5] = { 1, 3, 2, 5, 4 };
```
=== "Kotlin"
```kotlin title="array.kt"
/* 配列を初期化する */
var arr = IntArray(5) // { 0, 0, 0, 0, 0 }
var nums = intArrayOf(1, 3, 2, 5, 4)
```
=== "Ruby"
```ruby title="array.rb"
# 配列を初期化する
arr = Array.new(5, 0)
nums = [1, 3, 2, 5, 4]
```
??? pythontutor "実行の可視化"
https://pythontutor.com/render.html#code=%23%20%E5%88%9D%E5%A7%8B%E5%8C%96%E6%95%B0%E7%BB%84%0Aarr%20%3D%20%5B0%5D%20*%205%20%20%23%20%5B%200,%200,%200,%200,%200%20%5D%0Anums%20%3D%20%5B1,%203,%202,%205,%204%5D&cumulative=false&curInstr=0&heapPrimitives=nevernest&mode=display&origin=opt-frontend.js&py=311&rawInputLstJSON=%5B%5D&textReferences=false
### 要素へのアクセス
配列要素は連続したメモリ領域に格納されるため、要素のメモリアドレスの計算は非常に容易です。配列のメモリアドレス(先頭要素のメモリアドレス)とある要素のインデックスが与えられれば、下図の式を使ってその要素のメモリアドレスを計算でき、直接その要素にアクセスできます。

上図を見ると、配列の最初の要素のインデックスは $0$ であり、これは少し直感に反するように思えます。というのも、$1$ から数え始めるほうが自然だからです。しかし、アドレス計算式の観点では、**インデックスの本質はメモリアドレスのオフセット**です。先頭要素のアドレスのオフセットは $0$ であるため、そのインデックスが $0$ なのは妥当です。
配列では要素へのアクセスは非常に効率的であり、$O(1)$ 時間で任意の要素にランダムアクセスできます。
```src
[file]{array}-[class]{}-[func]{random_access}
```
### 要素の挿入
配列要素はメモリ内で「ぴったり隣接して」おり、その間にほかのデータを格納する余地はありません。下図のように、配列の途中に要素を挿入したい場合は、その要素より後ろにあるすべての要素を 1 つずつ後ろへずらし、その後でそのインデックスに要素を代入する必要があります。

注意すべき点として、配列の長さは固定であるため、要素を 1 つ挿入すると配列末尾の要素が必ず「失われ」ます。この問題の解決策は「リスト」の章で扱います。
```src
[file]{array}-[class]{}-[func]{insert}
```
### 要素の削除
同様に、下図のように、インデックス $i$ の要素を削除したい場合は、インデックス $i$ より後ろの要素をすべて 1 つずつ前へずらす必要があります。

注意してください。要素の削除が完了すると、もともとの末尾要素は「意味を持たない」状態になるため、わざわざ変更する必要はありません。
```src
[file]{array}-[class]{}-[func]{remove}
```
全体として見ると、配列の挿入と削除には次の欠点があります。
- **時間計算量が高い**:配列の挿入と削除の平均時間計算量はいずれも $O(n)$ であり、ここで $n$ は配列長です。
- **要素が失われる**:配列の長さは不変であるため、要素を挿入すると配列長の範囲を超えた要素は失われます。
- **メモリの浪費**:やや長めの配列を初期化して先頭部分だけを使うこともでき、この場合データ挿入時に失われる末尾要素はすべて「無意味」ですが、その代わり一部のメモリ領域が無駄になります。
### 配列の走査
ほとんどのプログラミング言語では、インデックスを使って配列を走査することも、各要素を直接取り出しながら走査することもできます。
```src
[file]{array}-[class]{}-[func]{traverse}
```
### 要素の検索
配列内で指定した要素を探すには、配列を走査し、各反復で要素値が一致するかを判定し、一致したら対応するインデックスを出力します。
配列は線形データ構造であるため、上記の検索操作は「線形探索」と呼ばれます。
```src
[file]{array}-[class]{}-[func]{find}
```
### 配列の拡張
複雑なシステム環境では、配列の後方にあるメモリ領域が利用可能であることをプログラム側で保証できず、そのため安全に配列容量を拡張できません。したがって、ほとんどのプログラミング言語では、**配列の長さは不変です**。
配列を拡張したい場合は、より大きな新しい配列を作り、元の配列の要素を順に新配列へコピーする必要があります。これは $O(n)$ の操作であり、配列が大きい場合は非常に時間がかかります。コードは次のとおりです。
```src
[file]{array}-[class]{}-[func]{extend}
```
## 配列の利点と限界
配列は連続したメモリ領域に格納され、要素の型も同一です。この方法には豊富な事前情報が含まれており、システムはそれらを利用してデータ構造の操作効率を最適化できます。
- **空間効率が高い**:配列はデータに連続したメモリブロックを割り当てるため、追加の構造オーバーヘッドが不要です。
- **ランダムアクセスをサポートする**:配列では任意の要素に $O(1)$ 時間でアクセスできます。
- **キャッシュ局所性**:配列要素にアクセスする際、コンピュータはその要素だけでなく周囲のデータもキャッシュするため、高速キャッシュを利用して後続操作の実行速度を高められます。
連続領域への格納は諸刃の剣であり、次のような制約があります。
- **挿入と削除の効率が低い**:配列内の要素が多い場合、挿入や削除では大量の要素を移動する必要があります。
- **長さが不変**:配列は初期化後に長さが固定され、拡張するにはすべてのデータを新しい配列へコピーする必要があり、コストが大きくなります。
- **空間の浪費**:配列に割り当てたサイズが実際の必要量を上回る場合、余分な領域は無駄になります。
## 配列の典型的な応用
配列は基礎的で一般的なデータ構造であり、さまざまなアルゴリズムで頻繁に使われるだけでなく、多様な複雑データ構造の実装にも利用できます。
- **ランダムアクセス**:いくつかのサンプルをランダムに抽出したい場合、配列に格納してランダムな系列を生成し、インデックスに基づいてランダムサンプリングを行えます。
- **ソートと探索**:配列はソートアルゴリズムと探索アルゴリズムで最もよく使われるデータ構造です。クイックソート、マージソート、二分探索などは主に配列上で行われます。
- **ルックアップテーブル**:ある要素やその対応関係を高速に調べる必要がある場合、配列をルックアップテーブルとして使えます。たとえば文字から ASCII コードへの対応を実装したいなら、文字の ASCII コード値をインデックスとし、対応する要素を配列の対応位置に格納できます。
- **機械学習**:ニューラルネットワークでは、ベクトル、行列、テンソル間の線形代数演算が大量に使われ、これらのデータはいずれも配列の形で構築されます。配列はニューラルネットワークプログラミングで最もよく使われるデータ構造です。
- **データ構造の実装**:配列はスタック、キュー、ハッシュテーブル、ヒープ、グラフなどのデータ構造の実装に利用できます。たとえば、グラフの隣接行列表現は実際には 2 次元配列です。