10 KiB
今天我们学习AdaBoost算法。在数据挖掘中,分类算法可以说是核心算法,其中AdaBoost算法与随机森林算法一样都属于分类算法中的集成算法。
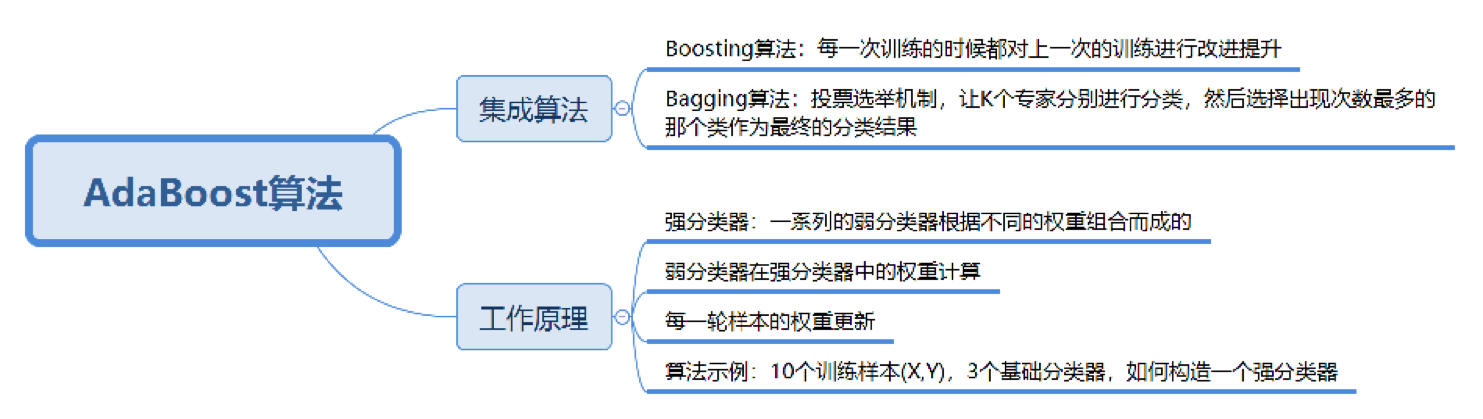
集成的含义就是集思广益,博取众长,当我们做决定的时候,我们先听取多个专家的意见,再做决定。集成算法通常有两种方式,分别是投票选举(bagging)和再学习(boosting)。投票选举的场景类似把专家召集到一个会议桌前,当做一个决定的时候,让K个专家(K个模型)分别进行分类,然后选择出现次数最多的那个类作为最终的分类结果。再学习相当于把K个专家(K个分类器)进行加权融合,形成一个新的超级专家(强分类器),让这个超级专家做判断。
所以你能看出来,投票选举和再学习还是有区别的。Boosting的含义是提升,它的作用是每一次训练的时候都对上一次的训练进行改进提升,在训练的过程中这K个“专家”之间是有依赖性的,当引入第K个“专家”(第K个分类器)的时候,实际上是对前K-1个专家的优化。而bagging在做投票选举的时候可以并行计算,也就是K个“专家”在做判断的时候是相互独立的,不存在依赖性。
AdaBoost的工作原理
了解了集成算法的两种模式之后,我们来看下今天要讲的AdaBoost算法。
AdaBoost的英文全称是Adaptive Boosting,中文含义是自适应提升算法。它由Freund等人于1995年提出,是对Boosting算法的一种实现。
什么是Boosting算法呢?Boosting算法是集成算法中的一种,同时也是一类算法的总称。这类算法通过训练多个弱分类器,将它们组合成一个强分类器,也就是我们俗话说的“三个臭皮匠,顶个诸葛亮”。为什么要这么做呢?因为臭皮匠好训练,诸葛亮却不好求。因此要打造一个诸葛亮,最好的方式就是训练多个臭皮匠,然后让这些臭皮匠组合起来,这样往往可以得到很好的效果。这就是Boosting算法的原理。
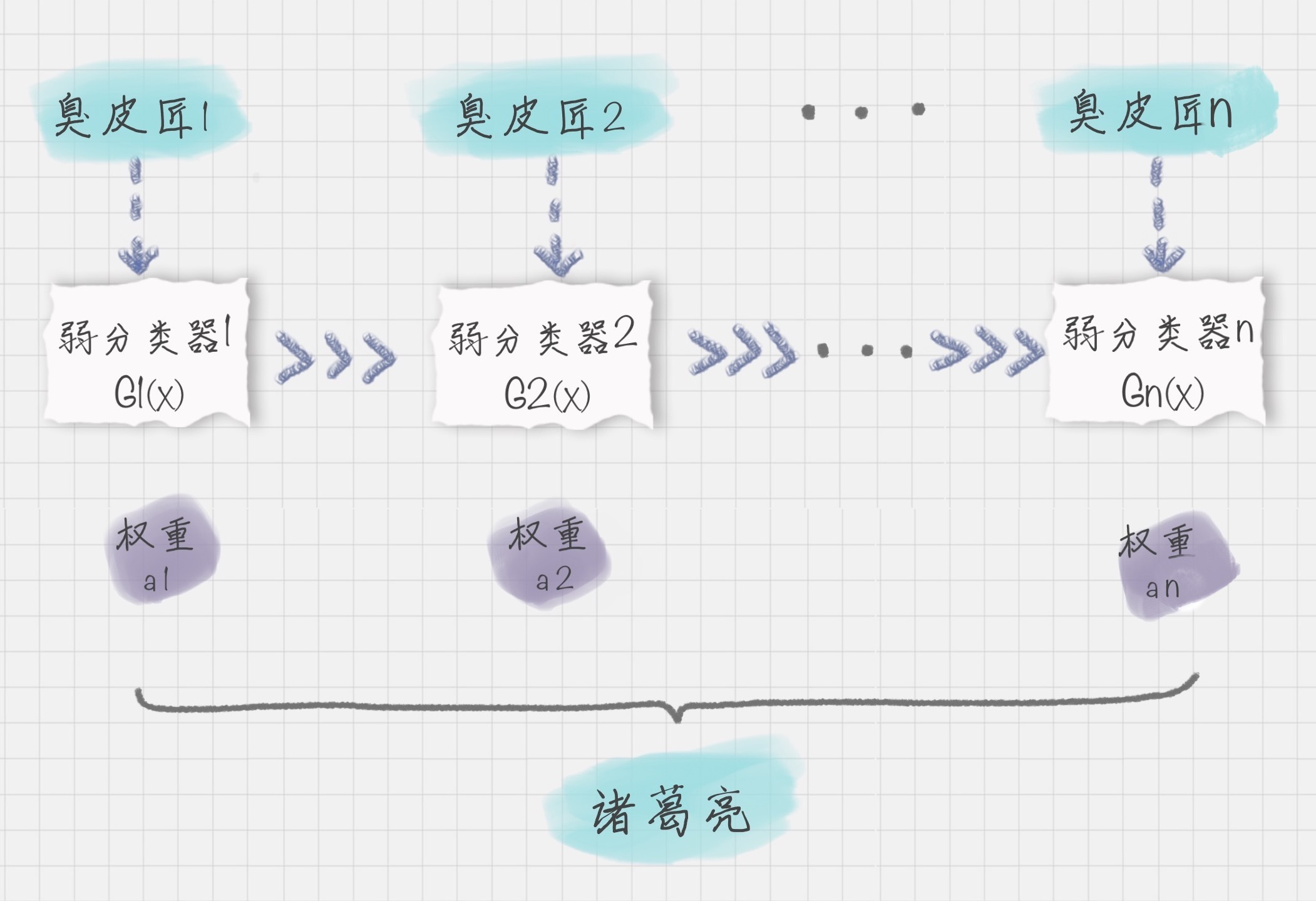
我可以用上面的图来表示最终得到的强分类器,你能看出它是通过一系列的弱分类器根据不同的权重组合而成的。
假设弱分类器为$G_{i}(x)$,它在强分类器中的权重$α_{i}$,那么就可以得出强分类器f(x):
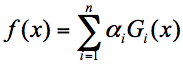
有了这个公式,为了求解强分类器,你会关注两个问题:
我们先来看下第二个问题。实际上在一个由K个弱分类器中组成的强分类器中,如果弱分类器的分类效果好,那么权重应该比较大,如果弱分类器的分类效果一般,权重应该降低。所以我们需要基于这个弱分类器对样本的分类错误率来决定它的权重,用公式表示就是:
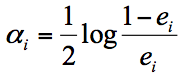
其中$e_{i}$代表第i个分类器的分类错误率。
然后我们再来看下第一个问题,如何在每次训练迭代的过程中选择最优的弱分类器?
实际上,AdaBoost算法是通过改变样本的数据分布来实现的。AdaBoost会判断每次训练的样本是否正确分类,对于正确分类的样本,降低它的权重,对于被错误分类的样本,增加它的权重。再基于上一次得到的分类准确率,来确定这次训练样本中每个样本的权重。然后将修改过权重的新数据集传递给下一层的分类器进行训练。这样做的好处就是,通过每一轮训练样本的动态权重,可以让训练的焦点集中到难分类的样本上,最终得到的弱分类器的组合更容易得到更高的分类准确率。
我们可以用$D_{k+1}$代表第k+1轮训练中,样本的权重集合,其中$W_{k+1,1}$代表第k+1轮中第一个样本的权重,以此类推$W_{k+1,N}$代表第k+1轮中第N个样本的权重,因此用公式表示为:
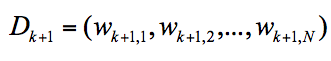
第k+1轮中的样本权重,是根据该样本在第k轮的权重以及第k个分类器的准确率而定,具体的公式为:
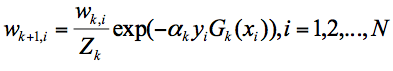
AdaBoost算法示例
了解AdaBoost的工作原理之后,我们看一个例子,假设我有10个训练样本,如下所示:

现在我希望通过AdaBoost构建一个强分类器。
该怎么做呢?按照上面的AdaBoost工作原理,我们来模拟一下。
首先在第一轮训练中,我们得到10个样本的权重为1/10,即初始的10个样本权重一致,D1=(0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1)。
假设我有3个基础分类器:
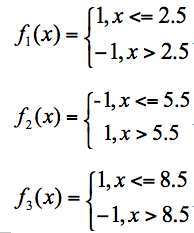
我们可以知道分类器f1的错误率为0.3,也就是x取值6、7、8时分类错误;分类器f2的错误率为0.4,即x取值0、1、2、9时分类错误;分类器f3的错误率为0.3,即x取值为3、4、5时分类错误。
这3个分类器中,f1、f3分类器的错误率最低,因此我们选择f1或f3作为最优分类器,假设我们选f1分类器作为最优分类器,即第一轮训练得到:
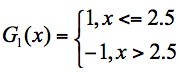
根据分类器权重公式得到:
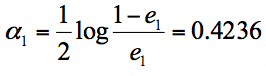
然后我们对下一轮的样本更新求权重值,代入$W_{k+1,i}$和$D_{k+1}$的公式,可以得到新的权重矩阵:D2=(0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。
在第二轮训练中,我们继续统计三个分类器的准确率,可以得到分类器f1的错误率为0.16663,也就是x取值为6、7、8时分类错误。分类器f2的错误率为0.07154,即x取值为0、1、2、9时分类错误。分类器f3的错误率为0.0715*3,即x取值3、4、5时分类错误。
在这3个分类器中,f3分类器的错误率最低,因此我们选择f3作为第二轮训练的最优分类器,即:
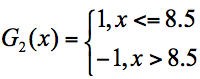
根据分类器权重公式得到:
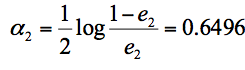
同样,我们对下一轮的样本更新求权重值,代入$W_{k+1,i}$和$D_{k+1}$的公式,可以得到D3=(0.0455,0.0455,0.0455,0.1667, 0.1667,0.01667,0.1060, 0.1060, 0.1060, 0.0455)。
在第三轮训练中,我们继续统计三个分类器的准确率,可以得到分类器f1的错误率为0.10603,也就是x取值6、7、8时分类错误。分类器f2的错误率为0.04554,即x取值为0、1、2、9时分类错误。分类器f3的错误率为0.1667*3,即x取值3、4、5时分类错误。
在这3个分类器中,f2分类器的错误率最低,因此我们选择f2作为第三轮训练的最优分类器,即:
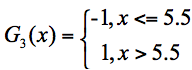
我们根据分类器权重公式得到:
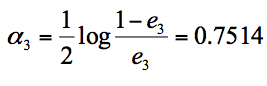
假设我们只进行3轮的训练,选择3个弱分类器,组合成一个强分类器,那么最终的强分类器G(x) = 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)。
实际上AdaBoost算法是一个框架,你可以指定任意的分类器,通常我们可以采用CART分类器作为弱分类器。通过上面这个示例的运算,你体会一下AdaBoost的计算流程即可。
总结
今天我给你讲了AdaBoost算法的原理,你可以把它理解为一种集成算法,通过训练不同的弱分类器,将这些弱分类器集成起来形成一个强分类器。在每一轮的训练中都会加入一个新的弱分类器,直到达到足够低的错误率或者达到指定的最大迭代次数为止。实际上每一次迭代都会引入一个新的弱分类器(这个分类器是每一次迭代中计算出来的,是新的分类器,不是事先准备好的)。
在弱分类器的集合中,你不必担心弱分类器太弱了。实际上它只需要比随机猜测的效果略好一些即可。如果随机猜测的准确率是50%的话,那么每个弱分类器的准确率只要大于50%就可用。AdaBoost的强大在于迭代训练的机制,这样通过K个“臭皮匠”的组合也可以得到一个“诸葛亮”(强分类器)。
当然在每一轮的训练中,我们都需要从众多“臭皮匠”中选择一个拔尖的,也就是这一轮训练评比中的最优“臭皮匠”,对应的就是错误率最低的分类器。当然每一轮的样本的权重都会发生变化,这样做的目的是为了让之前错误分类的样本得到更多概率的重复训练机会。
同样的原理在我们的学习生活中也经常出现,比如善于利用错题本来提升学习效率和学习成绩。
最后你能说说你是如何理解AdaBoost中弱分类器,强分类器概念的?另外,AdaBoost算法是如何训练弱分类器从而得到一个强分类器的?
欢迎你在评论区与我分享你的答案,也欢迎点击“请朋友读”,把这篇文章分享给你的朋友或者同事。