17 KiB
你好,我是王喆。
上节课,我们知道了推荐系统要使用的常用特征有哪些。但这些原始的特征是无法直接提供给推荐模型使用的,因为推荐模型本质上是一个函数,输入输出都是数字或数值型的向量。那么问题来了,像动作、喜剧、爱情、科幻这些电影风格,是怎么转换成数值供推荐模型使用的呢?用户的行为历史又是怎么转换成数值特征的呢?
而且,类似的特征处理过程在数据量变大之后还会变得更加复杂,因为工业界的数据集往往都是TB甚至PB规模的,这在单机上肯定是没法处理的。那业界又是怎样进行海量数据的特征处理呢?这节课,我就带你一起来解决这几个问题。
业界主流的大数据处理利器:Spark
既然要处理海量数据,那选择哪个数据处理平台就是我们首先要解决的问题。如果我们随机采访几位推荐系统领域的程序员,问他们在公司用什么平台处理大数据,我想最少有一半以上会回答是Spark。作为业界主流的大数据处理利器,Spark的地位毋庸置疑。所以,今天我先带你了解一下Spark的特点,再一起来看怎么用Spark处理推荐系统的特征。
Spark是一个分布式计算平台。所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。Spark最典型的应用方式就是建立在大量廉价的计算节点上,这些节点可以是廉价主机,也可以是虚拟的Docker Container(Docker容器)。
理解了Spark的基本概念,我们来看看它的架构。从下面Spark的架构图中我们可以看到,Spark程序由Manager Node(管理节点)进行调度组织,由Worker Node(工作节点)进行具体的计算任务执行,最终将结果返回给Drive Program(驱动程序)。在物理的Worker Node上,数据还会分为不同的partition(数据分片),可以说partition是Spark的基础数据单元。

Spark计算集群能够比传统的单机高性能服务器具备更强大的计算能力,就是由这些成百上千,甚至达到万以上规模的工作节点并行工作带来的。
那在执行一个具体任务的时候,**Spark是怎么协同这么多的工作节点,通过并行计算得出最终的结果呢?**这里我们用一个任务来解释一下Spark的工作过程。
这个任务并不复杂,我们需要先从本地硬盘读取文件textFile,再从分布式文件系统HDFS读取文件hadoopFile,然后分别对它们进行处理,再把两个文件按照ID都join起来得到最终的结果。
这里你没必要执着于任务的细节,只要清楚任务的大致流程就好。在Spark平台上处理这个任务的时候,会将这个任务拆解成一个子任务DAG(Directed Acyclic Graph,有向无环图),再根据DAG决定程序各步骤执行的方法。从图2中我们可以看到,这个Spark程序分别从textFile和hadoopFile读取文件,再经过一系列map、filter等操作后进行join,最终得到了处理结果。

其中,最关键的过程是我们要理解哪些是可以纯并行处理的部分,哪些是必须shuffle(混洗)和reduce的部分。
这里的shuffle指的是所有partition的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是图2中的groupByKey操作和join操作。以join操作为例,我们必须对textFile数据和hadoopFile数据做全量的匹配才可以得到join后的dataframe(Spark保存数据的结构)。而groupByKey操作则需要对数据中所有相同的key进行合并,也需要全局的shuffle才能完成。
与之相比,map、filter等操作仅需要逐条地进行数据处理和转换,不需要进行数据间的操作,因此各partition之间可以完全并行处理。
此外,在得到最终的计算结果之前,程序需要进行reduce的操作,从各partition上汇总统计结果,随着partition的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到master节点(主节点)上。可以说,shuffle和reduce操作的触发决定了纯并行处理阶段的边界。

最后,我还想强调的是,shuffle操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此shuffle操作是spark程序应该尽量避免的。
说了这么多,这里我们再用一句话总结Spark的计算过程:Stage内部数据高效并行计算,Stage边界处进行消耗资源的shuffle操作或者最终的reduce操作。
清楚了Spark的原理,相信你已经摩拳擦掌期待将Spark应用在推荐系统的特征处理上了。下面,我们就进入实战阶段,用Spark处理我们的Sparrow Recsys项目的数据集。在开始学习之前,我希望你能带着2个问题,边学边思考: 经典的特征处理方法有什么?Spark是如何实现这些特征处理方法的?
如何利用One-hot编码处理类别型特征
广义上来讲,所有的特征都可以分为两大类。第一类是类别、ID型特征(以下简称类别型特征)。拿电影推荐来说,电影的风格、ID、标签、导演演员等信息,用户看过的电影ID、用户的性别、地理位置信息、当前的季节、时间(上午,下午,晚上)、天气等等,这些无法用数字表示的信息全都可以被看作是类别、ID类特征。第二类是数值型特征,能用数字直接表示的特征就是数值型特征,典型的包括用户的年龄、收入、电影的播放时长、点击量、点击率等。
我们进行特征处理的目的,是把所有的特征全部转换成一个数值型的特征向量,对于数值型特征,这个过程非常简单,直接把这个数值放到特征向量上相应的维度上就可以了。但是对于类别、ID类特征,我们应该怎么处理它们呢?
这里我们就要用到One-hot编码(也被称为独热编码),它是将类别、ID型特征转换成数值向量的一种最典型的编码方式。它通过把所有其他维度置为0,单独将当前类别或者ID对应的维度置为1的方式生成特征向量。这怎么理解呢?我们举例来说,假设某样本有三个特征,分别是星期、性别和城市,我们用 [Weekday=Tuesday, Gender=Male, City=London] 来表示,用One-hot编码对其进行数值化的结果。

从图4中我们可以看到,Weekday这个特征域有7个维度,Tuesday对应第2个维度,所以我把对应维度置为1。而Gender分为Male和Female,所以对应的One-hot编码就有两个维度,City特征域同理。
除了这些类别型特征外,ID型特征也经常使用One-hot编码。比如,在我们的SparrowRecsys中,用户U观看过电影M,这个行为是一个非常重要的用户特征,那我们应该如何向量化这个行为呢?其实也是使用One-hot编码。假设,我们的电影库中一共有1000部电影,电影M的ID是310(编号从0开始),那这个行为就可以用一个1000维的向量来表示,让第310维的元素为1,其他元素都为0。
下面,我们就看看SparrowRecsys是如何利用Spark完成这一过程的。这里,我们使用Spark的机器学习库MLlib来完成One-hot特征的处理。
其中,最主要的步骤是,我们先创建一个负责One-hot编码的转换器,OneHotEncoderEstimator,然后通过它的fit函数完成指定特征的预处理,并利用transform函数将原始特征转换成One-hot特征。实现思路大体上就是这样,具体的步骤你可以参考我下面给出的源码:
def oneHotEncoderExample(samples:DataFrame): Unit ={
//samples样本集中的每一条数据代表一部电影的信息,其中movieId为电影id
val samplesWithIdNumber = samples.withColumn("movieIdNumber", col("movieId").cast(sql.types.IntegerType))
//利用Spark的机器学习库Spark MLlib创建One-hot编码器
val oneHotEncoder = new OneHotEncoderEstimator()
.setInputCols(Array("movieIdNumber"))
.setOutputCols(Array("movieIdVector"))
.setDropLast(false)
//训练One-hot编码器,并完成从id特征到One-hot向量的转换
val oneHotEncoderSamples = oneHotEncoder.fit(samplesWithIdNumber).transform(samplesWithIdNumber)
//打印最终样本的数据结构
oneHotEncoderSamples.printSchema()
//打印10条样本查看结果
oneHotEncoderSamples.show(10)
_(参考 com.wzhe.sparrowrecsys.offline.spark.featureeng.FeatureEngineering__中的oneHotEncoderExample函数)_
One-hot编码也可以自然衍生成Multi-hot编码(多热编码)。比如,对于历史行为序列类、标签特征等数据来说,用户往往会与多个物品产生交互行为,或者一个物品被打上多个标签,这时最常用的特征向量生成方式就是把其转换成Multi-hot编码。在SparrowRecsys中,因为每个电影都是有多个Genre(风格)类别的,所以我们就可以用Multi-hot编码完成标签到向量的转换。你可以自己尝试着用Spark实现该过程,也可以参考SparrowRecsys项目中 multiHotEncoderExample的实现,我就不多说啦。
数值型特征的处理-归一化和分桶
下面,我们再好好聊一聊数值型特征的处理。你可能会问了,数值型特征本身不就是数字吗?直接放入特征向量不就好了,为什么还要处理呢?
实际上,我们主要讨论两方面问题,一是特征的尺度,二是特征的分布。
特征的尺度问题不难理解,比如在电影推荐中有两个特征,一个是电影的评价次数fr,一个是电影的平均评分fs。评价次数其实是一个数值无上限的特征,在SparrowRecsys所用MovieLens数据集上,fr 的范围一般在[0,10000]之间。对于电影的平均评分来说,因为我们采用了5分为满分的评分,所以特征fs的取值范围在[0,5]之间。
由于fr和fs 两个特征的尺度差距太大,如果我们把特征的原始数值直接输入推荐模型,就会导致这两个特征对于模型的影响程度有显著的区别。如果模型中未做特殊处理的话,fr这个特征由于波动范围高出fs几个量级,可能会完全掩盖fs作用,这当然是我们不愿意看到的。为此我们希望把两个特征的尺度拉平到一个区域内,通常是[0,1]范围,这就是所谓归一化。
归一化虽然能够解决特征取值范围不统一的问题,但无法改变特征值的分布。比如图5就显示了Sparrow Recsys中编号在前1000的电影平均评分分布。你可以很明显地看到,由于人们打分有“中庸偏上”的倾向,因此评分大量集中在3.5的附近,而且越靠近3.5的密度越大。这对于模型学习来说也不是一个好的现象,因为特征的区分度并不高。

这该怎么办呢?我们经常会用分桶的方式来解决特征值分布极不均匀的问题。所谓“分桶(Bucketing)”,就是将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶ID作为特征值。
在Spark MLlib中,分别提供了两个转换器MinMaxScaler和QuantileDiscretizer,来进行归一化和分桶的特征处理。它们的使用方法和之前介绍的OneHotEncoderEstimator一样,都是先用fit函数进行数据预处理,再用transform函数完成特征转换。下面的代码就是SparrowRecSys利用这两个转换器完成特征归一化和分桶的过程。
def ratingFeatures(samples:DataFrame): Unit ={
samples.printSchema()
samples.show(10)
//利用打分表ratings计算电影的平均分、被打分次数等数值型特征
val movieFeatures = samples.groupBy(col("movieId"))
.agg(count(lit(1)).as("ratingCount"),
avg(col("rating")).as("avgRating"),
variance(col("rating")).as("ratingVar"))
.withColumn("avgRatingVec", double2vec(col("avgRating")))
movieFeatures.show(10)
//分桶处理,创建QuantileDiscretizer进行分桶,将打分次数这一特征分到100个桶中
val ratingCountDiscretizer = new QuantileDiscretizer()
.setInputCol("ratingCount")
.setOutputCol("ratingCountBucket")
.setNumBuckets(100)
//归一化处理,创建MinMaxScaler进行归一化,将平均得分进行归一化
val ratingScaler = new MinMaxScaler()
.setInputCol("avgRatingVec")
.setOutputCol("scaleAvgRating")
//创建一个pipeline,依次执行两个特征处理过程
val pipelineStage: Array[PipelineStage] = Array(ratingCountDiscretizer, ratingScaler)
val featurePipeline = new Pipeline().setStages(pipelineStage)
val movieProcessedFeatures = featurePipeline.fit(movieFeatures).transform(movieFeatures)
//打印最终结果
movieProcessedFeatures.show(
_(参考 com.wzhe.sparrowrecsys.offline.spark.featureeng.FeatureEngineering中的ratingFeatures函数)_
当然,对于数值型特征的处理方法还远不止于此,在经典的YouTube深度推荐模型中,我们就可以看到一些很有意思的处理方法。比如,在处理观看时间间隔(time since last watch)和视频曝光量(#previous impressions)这两个特征的时,YouTube模型对它们进行归一化后,又将它们各自处理成了三个特征(图6中红框内的部分),分别是原特征值x,特征值的平方x^2,以及特征值的开方,这又是为什么呢?
")
其实,无论是平方还是开方操作,改变的还是这个特征值的分布,这些操作与分桶操作一样,都是希望通过改变特征的分布,让模型能够更好地学习到特征内包含的有价值信息。但由于我们没法通过人工的经验判断哪种特征处理方式更好,所以索性把它们都输入模型,让模型来做选择。
这里其实自然而然地引出了我们进行特征处理的一个原则,就是特征处理并没有标准答案,不存在一种特征处理方式是一定好于另一种的。在实践中,我们需要多进行一些尝试,找到那个最能够提升模型效果的一种或一组处理方式。
小结
这节课我们介绍了推荐系统中特征处理的主要方式,并利用Spark实践了类别型特征和数值型特征的主要处理方法,最后我们还总结出了特征处理的原则,“特征处理没有标准答案,需要根据模型效果实践出真知”。
针对特征处理的方法,深度学习和传统机器学习的区别并不大,TensorFlow、PyTorch等深度学习平台也提供了类似的特征处理函数。在今后的推荐模型章节我们会进一步用到这些方法。
最后,我把这节课的主要知识点总结成了一张表格,你可以利用它巩固今天的重点知识。
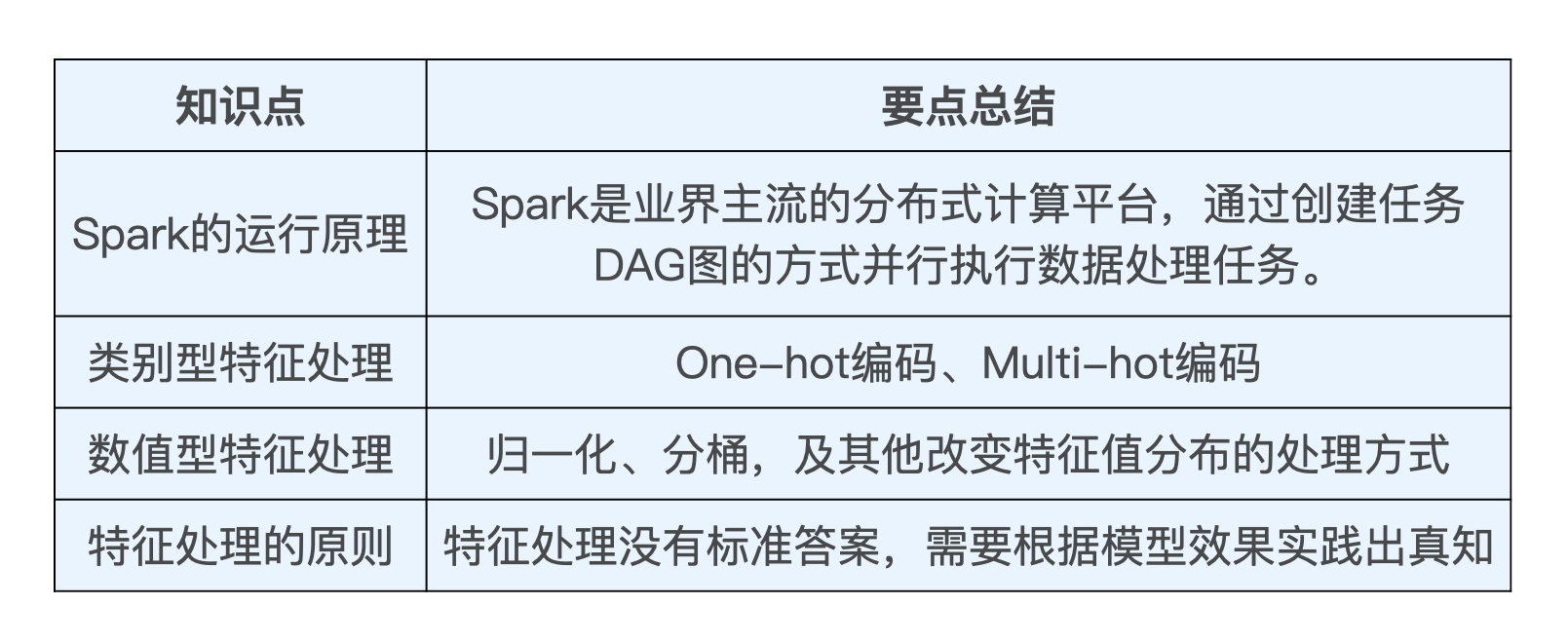
这节课是我们的第一堂实战课,对于还未进入到工业界的同学,相信通过这节课的实践,也能够一窥业界的大数据处理方法,增强自己的工程经验,让我们一起由此迈入工业级推荐系统的大门吧!
课后思考
这就是我们这节课的全部内容了,你掌握得怎么样?欢迎你把这节课转发出去。下节课我们将讲解一种更高阶的特征处理方法,它同时也是深度学习知识体系中一个非常重要的部分,我们到时候见!