mirror of
https://github.com/songquanpeng/one-api.git
synced 2025-10-23 18:03:41 +08:00
Compare commits
9 Commits
v0.3.2-alp
...
v0.3.2
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3711f4a741 | ||
|
|
7c6bf3e97b | ||
|
|
481ba41fbd | ||
|
|
2779d6629c | ||
|
|
e509899daf | ||
|
|
b53cdbaf05 | ||
|
|
ced89398a5 | ||
|
|
09c2e3bcec | ||
|
|
5cba800fa6 |
21
README.md
21
README.md
@@ -38,6 +38,8 @@ _✨ All in one 的 OpenAI 接口,整合各种 API 访问方式,开箱即用
|
||||
<a href="https://github.com/songquanpeng/one-api#截图展示">截图展示</a>
|
||||
·
|
||||
<a href="https://openai.justsong.cn/">在线演示</a>
|
||||
·
|
||||
<a href="https://github.com/songquanpeng/one-api#常见问题">常见问题</a>
|
||||
</p>
|
||||
|
||||
> **Warning**:从 `v0.2` 版本升级到 `v0.3` 版本需要手动迁移数据库,请手动执行[数据库迁移脚本](./bin/migration_v0.2-v0.3.sql)。
|
||||
@@ -49,9 +51,10 @@ _✨ All in one 的 OpenAI 接口,整合各种 API 访问方式,开箱即用
|
||||
+ [x] **Azure OpenAI API**
|
||||
+ [x] [API2D](https://api2d.com/r/197971)
|
||||
+ [x] [OhMyGPT](https://aigptx.top?aff=uFpUl2Kf)
|
||||
+ [x] [CloseAI](https://console.openai-asia.com)
|
||||
+ [x] [OpenAI-SB](https://openai-sb.com)
|
||||
+ [x] [AI.LS](https://ai.ls)
|
||||
+ [x] [OpenAI Max](https://openaimax.com)
|
||||
+ [x] [OpenAI-SB](https://openai-sb.com)
|
||||
+ [x] [CloseAI](https://console.openai-asia.com)
|
||||
+ [x] 自定义渠道:例如使用自行搭建的 OpenAI 代理
|
||||
2. 支持通过**负载均衡**的方式访问多个渠道。
|
||||
3. 支持 **stream 模式**,可以通过流式传输实现打字机效果。
|
||||
@@ -91,13 +94,10 @@ server{
|
||||
proxy_set_header X-Forwarded-For $remote_addr;
|
||||
proxy_cache_bypass $http_upgrade;
|
||||
proxy_set_header Accept-Encoding gzip;
|
||||
proxy_buffering off; # 重要:关闭代理缓冲
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
注意,为了 SSE 正常工作,需要关闭 Nginx 的代理缓冲。
|
||||
|
||||
之后使用 Let's Encrypt 的 certbot 配置 HTTPS:
|
||||
```bash
|
||||
# Ubuntu 安装 certbot:
|
||||
@@ -136,9 +136,9 @@ sudo service nginx restart
|
||||
|
||||
### 多机部署
|
||||
1. 所有服务器 `SESSION_SECRET` 设置一样的值。
|
||||
2. 必须设置 `SQL_DSN`,使用 MySQL 数据库而非 SQLite,请执行配置主备数据库同步。
|
||||
2. 必须设置 `SQL_DSN`,使用 MySQL 数据库而非 SQLite,请自行配置主备数据库同步。
|
||||
3. 所有从服务器必须设置 `SYNC_FREQUENCY`,以定期从数据库同步配置。
|
||||
4. 从服务器可以选择设置 `FRONTEND_BASE_URL`,以重定向页面请求到主服务器。‘
|
||||
4. 从服务器可以选择设置 `FRONTEND_BASE_URL`,以重定向页面请求到主服务器。
|
||||
|
||||
环境变量的具体使用方法详见[此处](#环境变量)。
|
||||
|
||||
@@ -187,3 +187,10 @@ https://openai.justsong.cn
|
||||
### 截图展示
|
||||
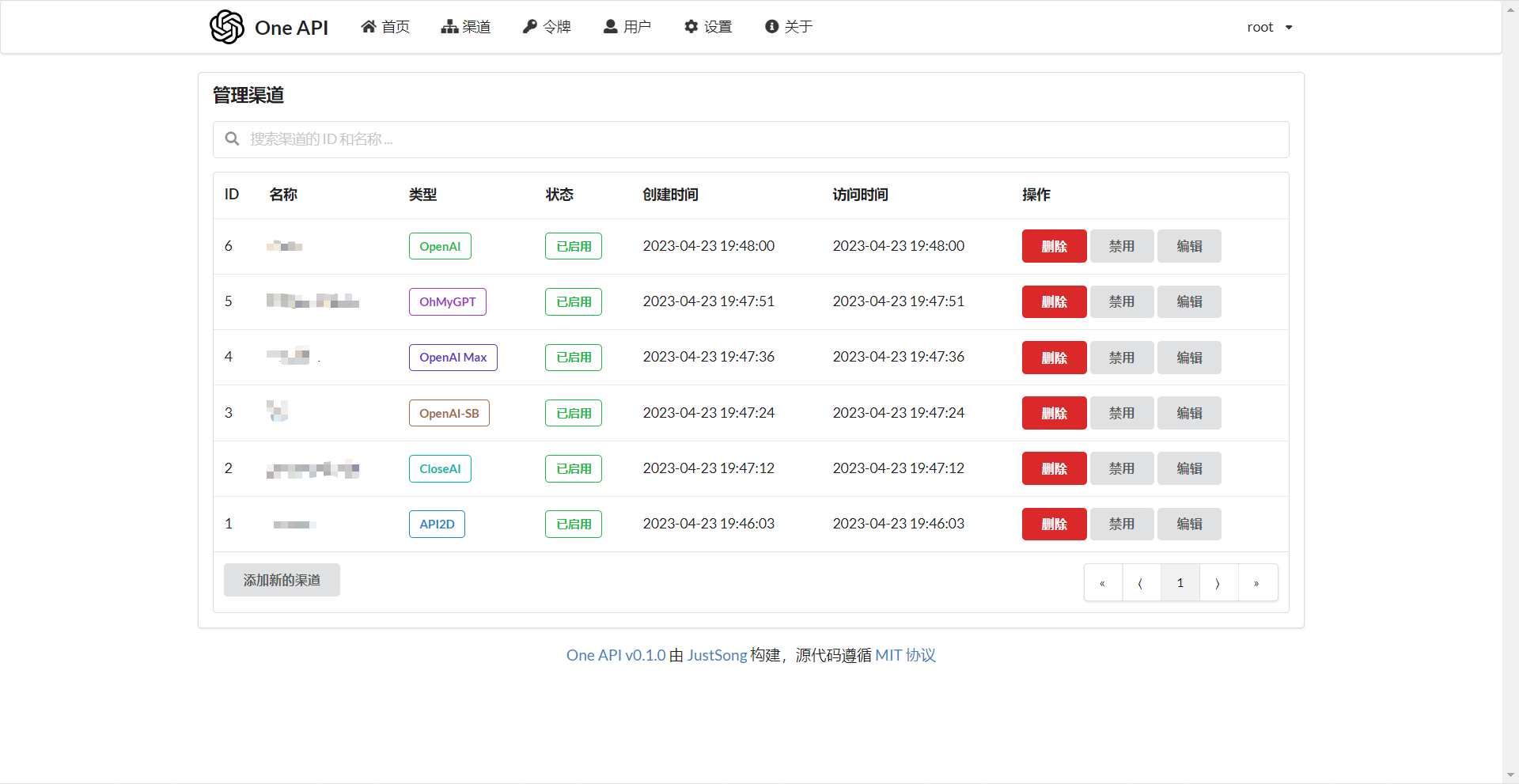
|
||||
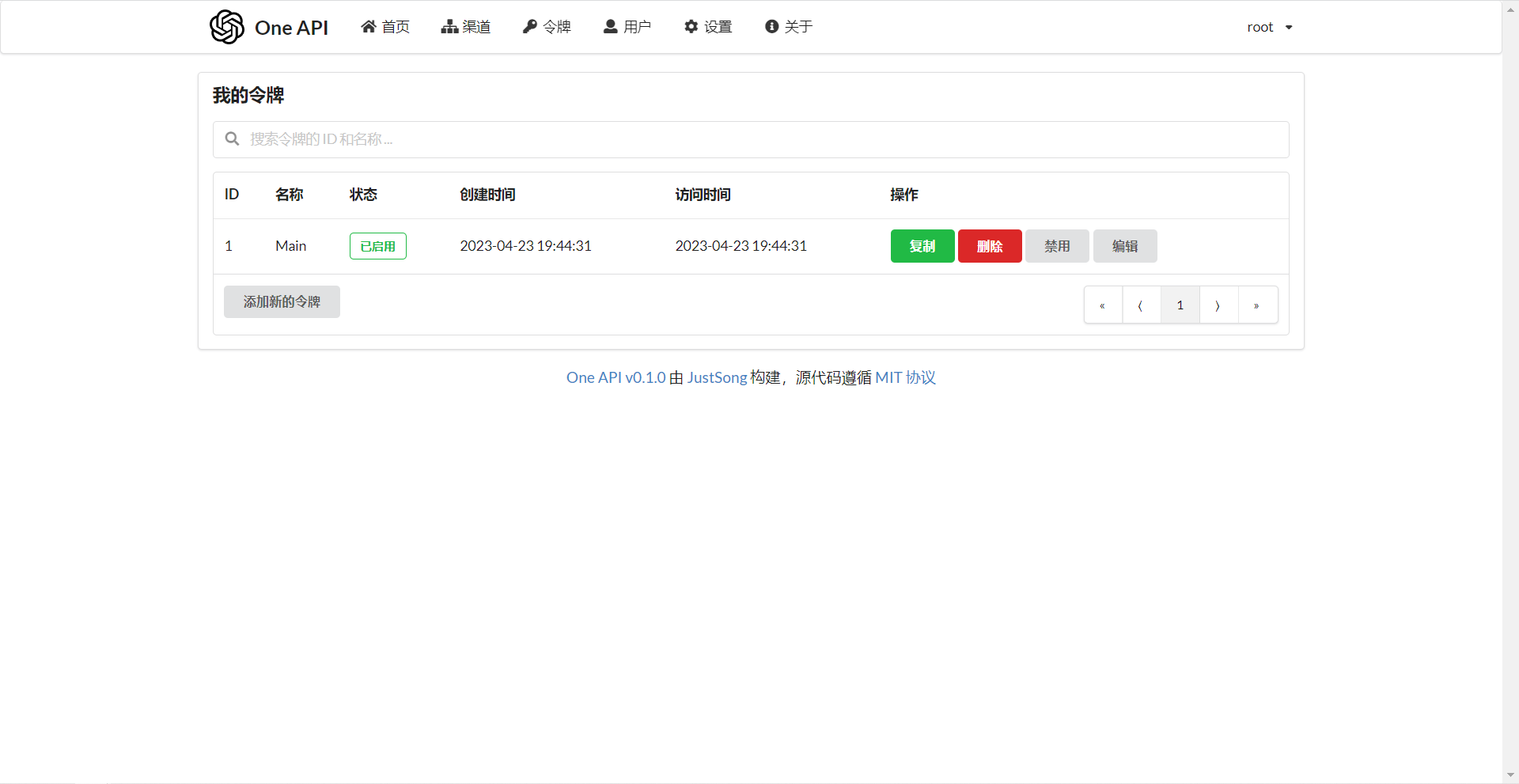
|
||||
|
||||
## 常见问题
|
||||
1. 账户额度足够为什么提示额度不足?
|
||||
+ 请检查你的令牌额度是否足够,这个和账户额度是分开的。
|
||||
+ 令牌额度仅供用户设置最大使用量,用户可自由设置。
|
||||
2. 宝塔部署后访问出现空白页面?
|
||||
+ 自动配置的问题,详见[#97](https://github.com/songquanpeng/one-api/issues/97)。
|
||||
@@ -127,6 +127,7 @@ const (
|
||||
ChannelTypeOpenAIMax = 6
|
||||
ChannelTypeOhMyGPT = 7
|
||||
ChannelTypeCustom = 8
|
||||
ChannelTypeAILS = 9
|
||||
)
|
||||
|
||||
var ChannelBaseURLs = []string{
|
||||
@@ -139,4 +140,5 @@ var ChannelBaseURLs = []string{
|
||||
"https://api.openaimax.com", // 6
|
||||
"https://api.ohmygpt.com", // 7
|
||||
"", // 8
|
||||
"https://api.caipacity.com", // 9
|
||||
}
|
||||
|
||||
61
controller/relay-utils.go
Normal file
61
controller/relay-utils.go
Normal file
@@ -0,0 +1,61 @@
|
||||
package controller
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/pkoukk/tiktoken-go"
|
||||
"one-api/common"
|
||||
"strings"
|
||||
)
|
||||
|
||||
var tokenEncoderMap = map[string]*tiktoken.Tiktoken{}
|
||||
|
||||
func getTokenEncoder(model string) *tiktoken.Tiktoken {
|
||||
if tokenEncoder, ok := tokenEncoderMap[model]; ok {
|
||||
return tokenEncoder
|
||||
}
|
||||
tokenEncoder, err := tiktoken.EncodingForModel(model)
|
||||
if err != nil {
|
||||
common.FatalLog(fmt.Sprintf("failed to get token encoder for model %s: %s", model, err.Error()))
|
||||
}
|
||||
tokenEncoderMap[model] = tokenEncoder
|
||||
return tokenEncoder
|
||||
}
|
||||
|
||||
func countTokenMessages(messages []Message, model string) int {
|
||||
tokenEncoder := getTokenEncoder(model)
|
||||
// Reference:
|
||||
// https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
|
||||
// https://github.com/pkoukk/tiktoken-go/issues/6
|
||||
//
|
||||
// Every message follows <|start|>{role/name}\n{content}<|end|>\n
|
||||
var tokensPerMessage int
|
||||
var tokensPerName int
|
||||
if strings.HasPrefix(model, "gpt-3.5") {
|
||||
tokensPerMessage = 4
|
||||
tokensPerName = -1 // If there's a name, the role is omitted
|
||||
} else if strings.HasPrefix(model, "gpt-4") {
|
||||
tokensPerMessage = 3
|
||||
tokensPerName = 1
|
||||
} else {
|
||||
tokensPerMessage = 3
|
||||
tokensPerName = 1
|
||||
}
|
||||
tokenNum := 0
|
||||
for _, message := range messages {
|
||||
tokenNum += tokensPerMessage
|
||||
tokenNum += len(tokenEncoder.Encode(message.Content, nil, nil))
|
||||
tokenNum += len(tokenEncoder.Encode(message.Role, nil, nil))
|
||||
if message.Name != nil {
|
||||
tokenNum += tokensPerName
|
||||
tokenNum += len(tokenEncoder.Encode(*message.Name, nil, nil))
|
||||
}
|
||||
}
|
||||
tokenNum += 3 // Every reply is primed with <|start|>assistant<|message|>
|
||||
return tokenNum
|
||||
}
|
||||
|
||||
func countTokenText(text string, model string) int {
|
||||
tokenEncoder := getTokenEncoder(model)
|
||||
token := tokenEncoder.Encode(text, nil, nil)
|
||||
return len(token)
|
||||
}
|
||||
@@ -6,7 +6,6 @@ import (
|
||||
"encoding/json"
|
||||
"fmt"
|
||||
"github.com/gin-gonic/gin"
|
||||
"github.com/pkoukk/tiktoken-go"
|
||||
"io"
|
||||
"net/http"
|
||||
"one-api/common"
|
||||
@@ -15,8 +14,9 @@ import (
|
||||
)
|
||||
|
||||
type Message struct {
|
||||
Role string `json:"role"`
|
||||
Content string `json:"content"`
|
||||
Role string `json:"role"`
|
||||
Content string `json:"content"`
|
||||
Name *string `json:"name,omitempty"`
|
||||
}
|
||||
|
||||
type ChatRequest struct {
|
||||
@@ -65,16 +65,12 @@ type StreamResponse struct {
|
||||
} `json:"choices"`
|
||||
}
|
||||
|
||||
var tokenEncoder, _ = tiktoken.GetEncoding("cl100k_base")
|
||||
|
||||
func countToken(text string) int {
|
||||
token := tokenEncoder.Encode(text, nil, nil)
|
||||
return len(token)
|
||||
}
|
||||
|
||||
func Relay(c *gin.Context) {
|
||||
err := relayHelper(c)
|
||||
if err != nil {
|
||||
if err.StatusCode == http.StatusTooManyRequests {
|
||||
err.OpenAIError.Message = "负载已满,请稍后再试,或升级账户以提升服务质量。"
|
||||
}
|
||||
c.JSON(err.StatusCode, gin.H{
|
||||
"error": err.OpenAIError,
|
||||
})
|
||||
@@ -146,11 +142,8 @@ func relayHelper(c *gin.Context) *OpenAIErrorWithStatusCode {
|
||||
model_ = strings.TrimSuffix(model_, "-0314")
|
||||
fullRequestURL = fmt.Sprintf("%s/openai/deployments/%s/%s", baseURL, model_, task)
|
||||
}
|
||||
var promptText string
|
||||
for _, message := range textRequest.Messages {
|
||||
promptText += fmt.Sprintf("%s: %s\n", message.Role, message.Content)
|
||||
}
|
||||
promptTokens := countToken(promptText) + 3
|
||||
|
||||
promptTokens := countTokenMessages(textRequest.Messages, textRequest.Model)
|
||||
preConsumedTokens := common.PreConsumedQuota
|
||||
if textRequest.MaxTokens != 0 {
|
||||
preConsumedTokens = promptTokens + textRequest.MaxTokens
|
||||
@@ -203,8 +196,8 @@ func relayHelper(c *gin.Context) *OpenAIErrorWithStatusCode {
|
||||
completionRatio = 2
|
||||
}
|
||||
if isStream {
|
||||
completionText := fmt.Sprintf("%s: %s\n", "assistant", streamResponseText)
|
||||
quota = promptTokens + countToken(completionText)*completionRatio
|
||||
responseTokens := countTokenText(streamResponseText, textRequest.Model)
|
||||
quota = promptTokens + responseTokens*completionRatio
|
||||
} else {
|
||||
quota = textResponse.Usage.PromptTokens + textResponse.Usage.CompletionTokens*completionRatio
|
||||
}
|
||||
@@ -239,6 +232,10 @@ func relayHelper(c *gin.Context) *OpenAIErrorWithStatusCode {
|
||||
go func() {
|
||||
for scanner.Scan() {
|
||||
data := scanner.Text()
|
||||
if len(data) < 6 { // must be something wrong!
|
||||
common.SysError("Invalid stream response: " + data)
|
||||
continue
|
||||
}
|
||||
dataChan <- data
|
||||
data = data[6:]
|
||||
if !strings.HasPrefix(data, "[DONE]") {
|
||||
@@ -259,6 +256,7 @@ func relayHelper(c *gin.Context) *OpenAIErrorWithStatusCode {
|
||||
c.Writer.Header().Set("Cache-Control", "no-cache")
|
||||
c.Writer.Header().Set("Connection", "keep-alive")
|
||||
c.Writer.Header().Set("Transfer-Encoding", "chunked")
|
||||
c.Writer.Header().Set("X-Accel-Buffering", "no")
|
||||
c.Stream(func(w io.Writer) bool {
|
||||
select {
|
||||
case data := <-dataChan:
|
||||
|
||||
@@ -6,5 +6,6 @@ export const CHANNEL_OPTIONS = [
|
||||
{ key: 5, text: 'OpenAI-SB', value: 5, color: 'brown' },
|
||||
{ key: 6, text: 'OpenAI Max', value: 6, color: 'violet' },
|
||||
{ key: 7, text: 'OhMyGPT', value: 7, color: 'purple' },
|
||||
{ key: 9, text: 'AI.LS', value: 9, color: 'yellow' },
|
||||
{ key: 8, text: '自定义', value: 8, color: 'pink' }
|
||||
];
|
||||
|
||||
Reference in New Issue
Block a user