9.4 KiB
One API
The original author of one-api has not been active for a long time, resulting in a backlog of PRs that cannot be updated. Therefore, I forked the code and merged some PRs that I consider important. I also welcome everyone to submit PRs, and I will respond and handle them actively and quickly.
Fully compatible with the upstream version, can be used directly by replacing the container image, docker images:
ppcelery/one-api:latestppcelery/one-api:arm64-latest
Also welcome to register and use my deployed one-api gateway, which supports various mainstream models. For usage instructions, please refer to https://wiki.laisky.com/projects/gpt/pay/cn/#page_gpt_pay_cn.
- One API
- Turtorial
- New Features
- (Merged) Support gpt-vision
- Support update user's remained quota
- (Merged) Support aws claude
- Support openai images edits
- Support gemini-2.0-flash-exp
- Support replicate flux & remix
- Support replicate chat models
- Support OpenAI o1/o1-mini/o1-preview
- Get request's cost
- Support Vertex Imagen3
- Support gpt-4o-audio
- Support deepseek-reasoner & gemini-2.0-flash-thinking-exp-01-21
- Support o3-mini
- Support gemini-2.0-flash
- Support OpenRouter's reasoning content
- Support claude-3-7-sonnet & thinking
- Automatically Enable Thinking and Customize Reasoning Format via URL Parameters
- Bug fix
Turtorial
Run one-api using docker-compose:
oneapi:
image: ppcelery/one-api:latest
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
environment:
# (optional) SESSION_SECRET set a fixed session secret so that user sessions won't be invalidated after server restart
SESSION_SECRET: xxxxxxx
# (optional) DEBUG enable debug mode
DEBUG: "true"
# (optional) DEBUG_SQL display SQL logs
DEBUG_SQL: "true"
# (optional) ENFORCE_INCLUDE_USAGE require upstream API responses to include usage field
ENFORCE_INCLUDE_USAGE: "true"
# (optional) GLOBAL_API_RATE_LIMIT maximum API requests per IP within three minutes, default is 1000
GLOBAL_API_RATE_LIMIT: 1000
# (optional) GLOBAL_WEB_RATE_LIMIT maximum web page requests per IP within three minutes, default is 1000
GLOBAL_WEB_RATE_LIMIT: 1000
# (optional) REDIS_CONN_STRING set REDIS cache connection
REDIS_CONN_STRING: redis://100.122.41.16:6379/1
# (optional) FRONTEND_BASE_URL redirect page requests to specified address, server-side setting only
FRONTEND_BASE_URL: https://oneapi.laisky.com
# (optional) OPENROUTER_PROVIDER_SORT set sorting method for OpenRouter Providers, default is throughput
OPENROUTER_PROVIDER_SORT: throughput
volumes:
- /var/lib/oneapi:/data
ports:
- 3000:3000
The initial default account and password are root / 123456.
New Features
(Merged) Support gpt-vision
Support update user's remained quota
You can update the used quota using the API key of any token, allowing other consumption to be aggregated into the one-api for centralized management.
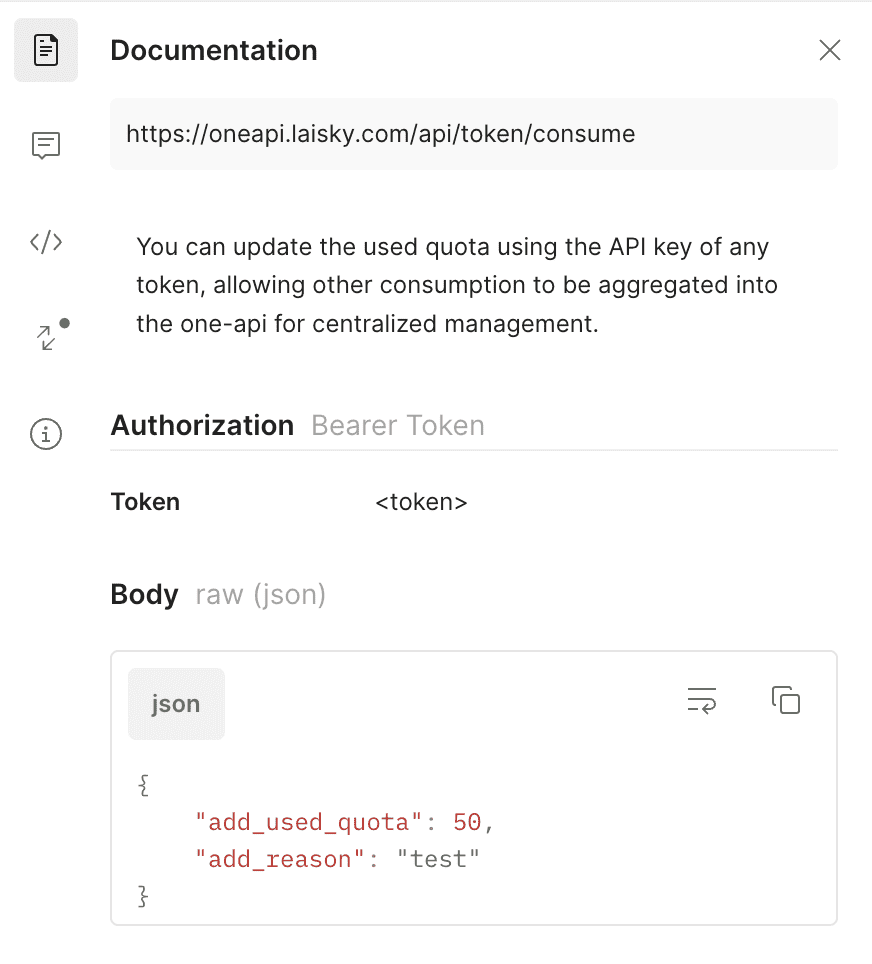
(Merged) Support aws claude
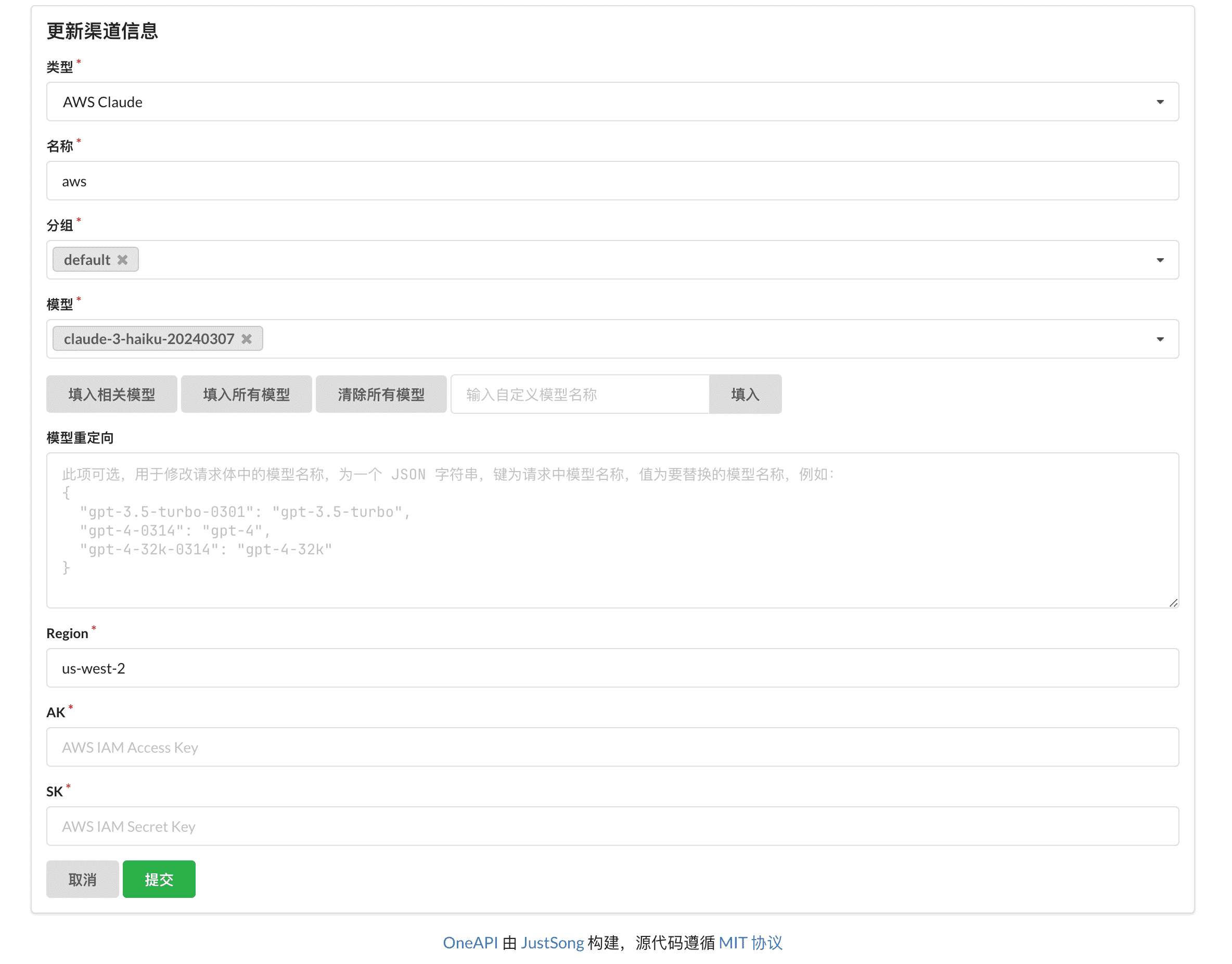
Support openai images edits
Support gemini-2.0-flash-exp

Support replicate flux & remix
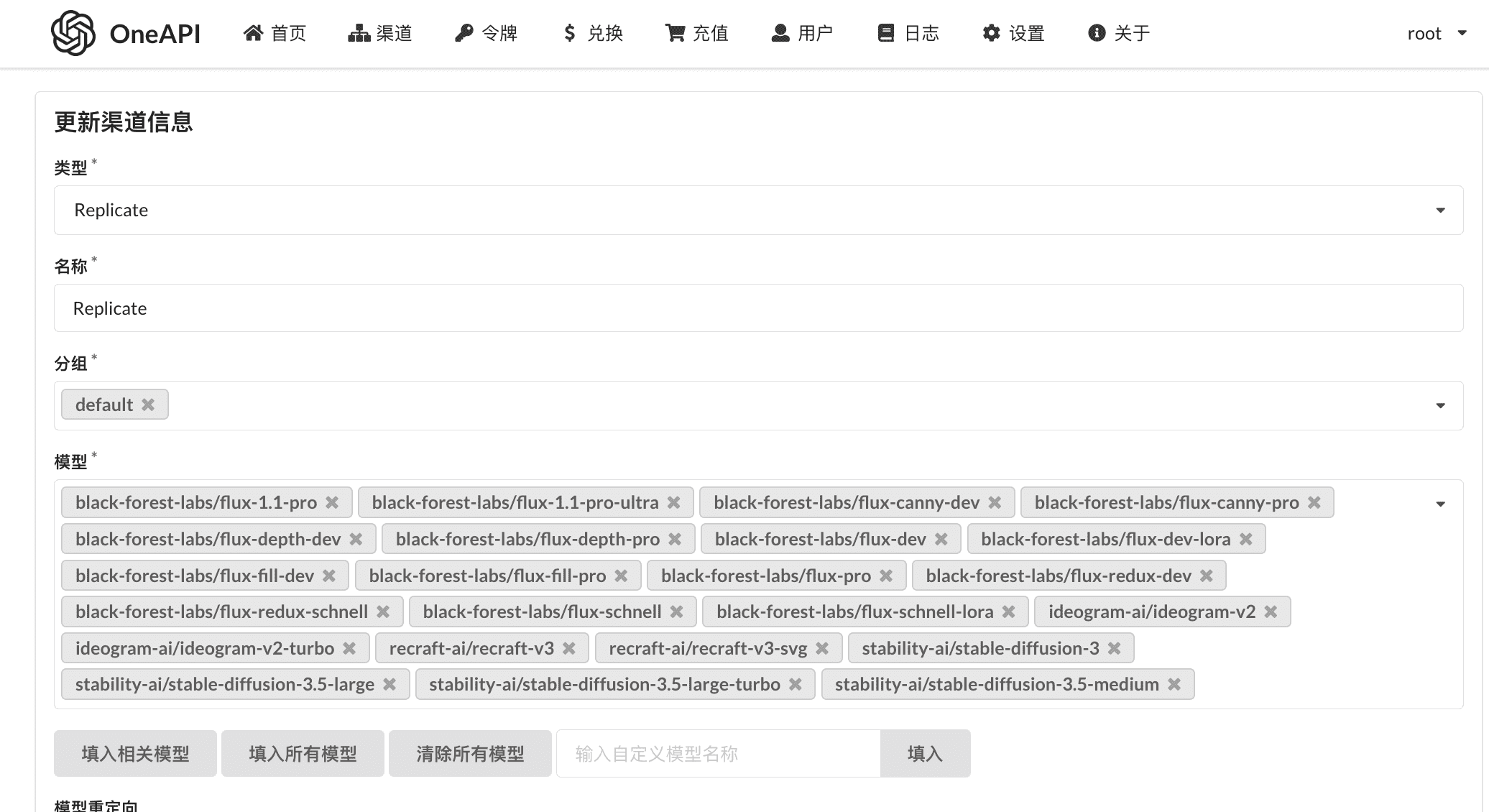
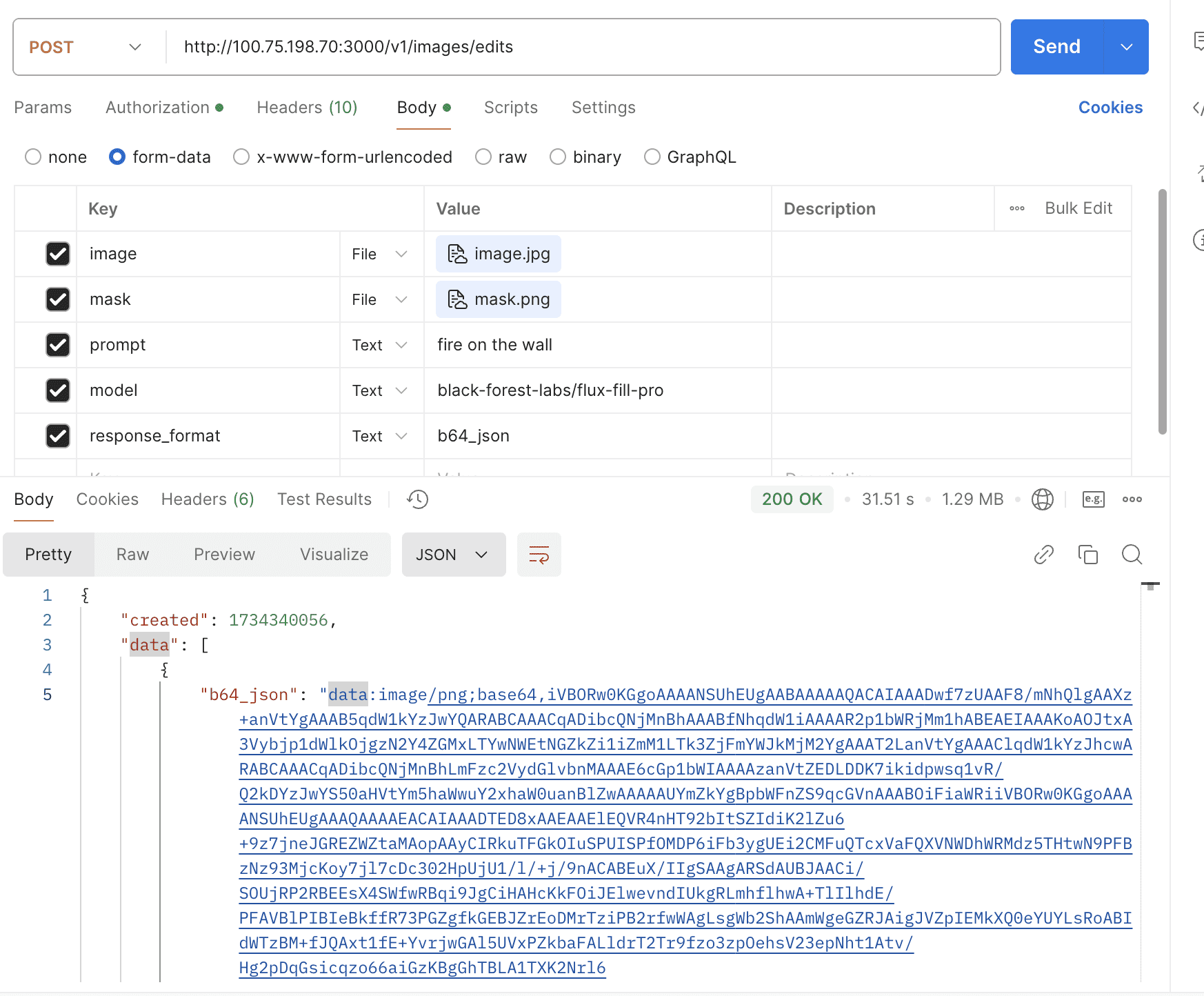

Support replicate chat models
Support OpenAI o1/o1-mini/o1-preview
Get request's cost
Each chat completion request will include a X-Oneapi-Request-Id in the returned headers. You can use this request id to request GET /api/cost/request/:request_id to get the cost of this request.
The returned structure is:
type UserRequestCost struct {
Id int `json:"id"`
CreatedTime int64 `json:"created_time" gorm:"bigint"`
UserID int `json:"user_id"`
RequestID string `json:"request_id"`
Quota int64 `json:"quota"`
CostUSD float64 `json:"cost_usd" gorm:"-"`
}
Support Vertex Imagen3
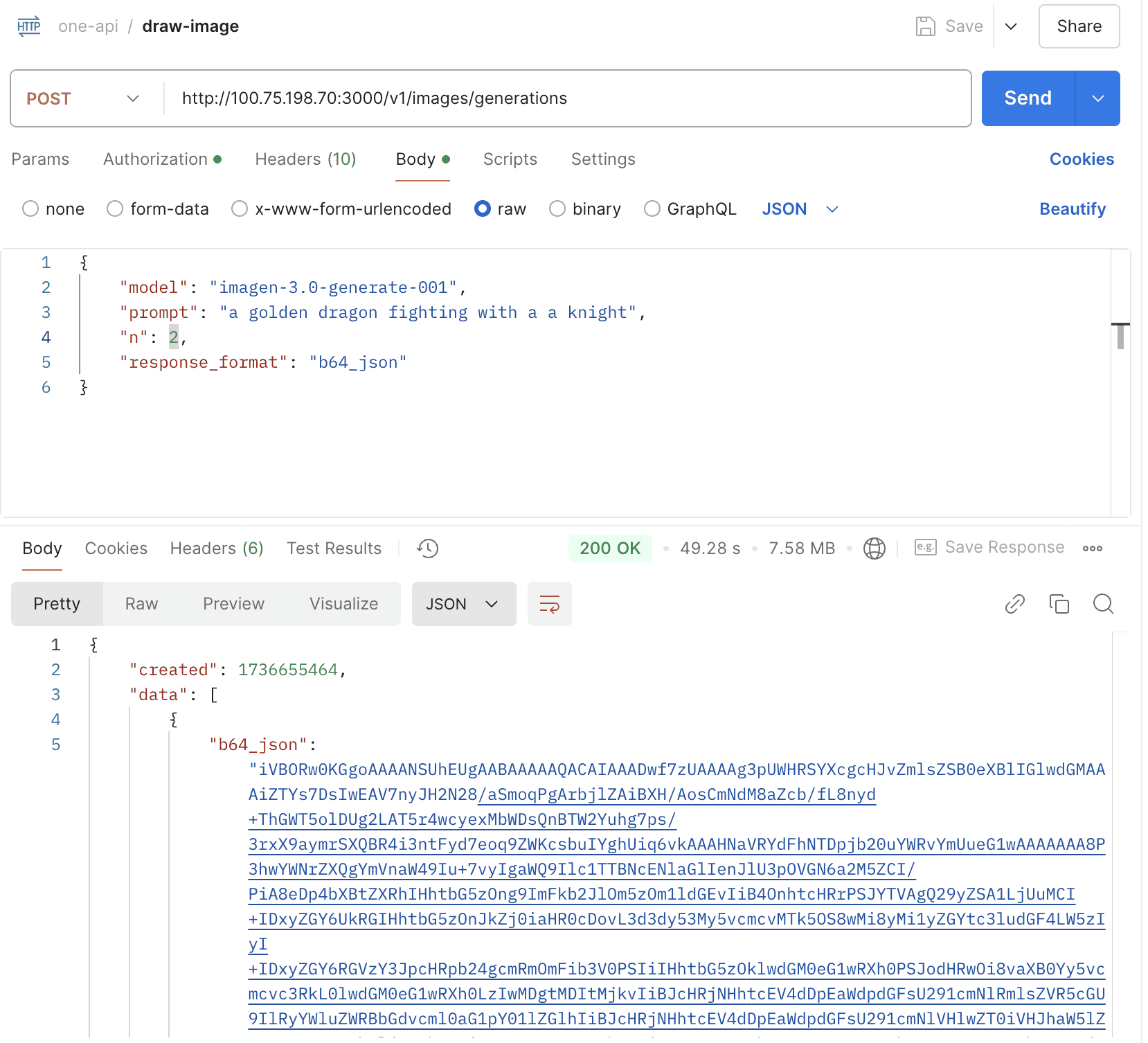
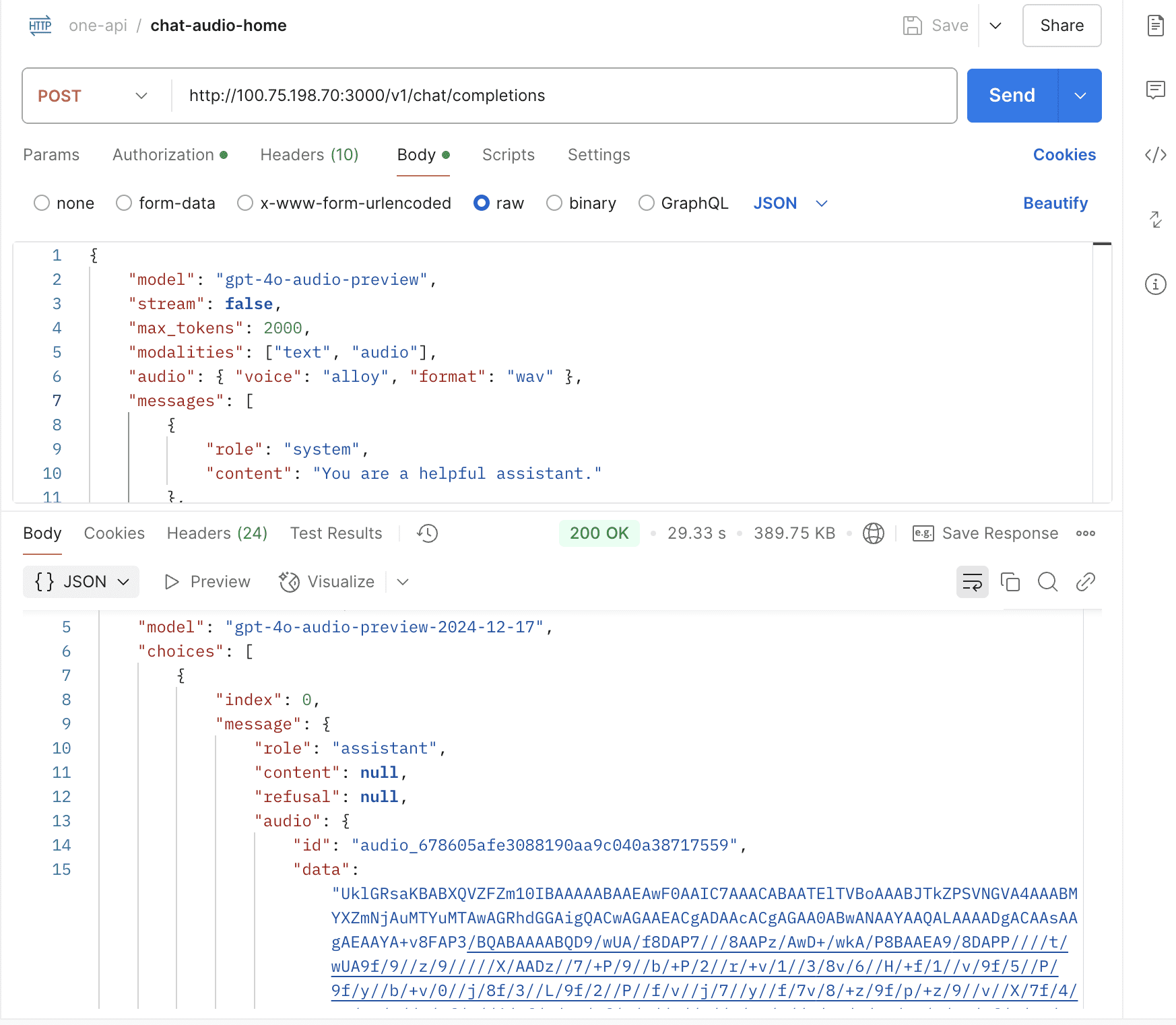
Support gpt-4o-audio

Support deepseek-reasoner & gemini-2.0-flash-thinking-exp-01-21
Support o3-mini
Support gemini-2.0-flash
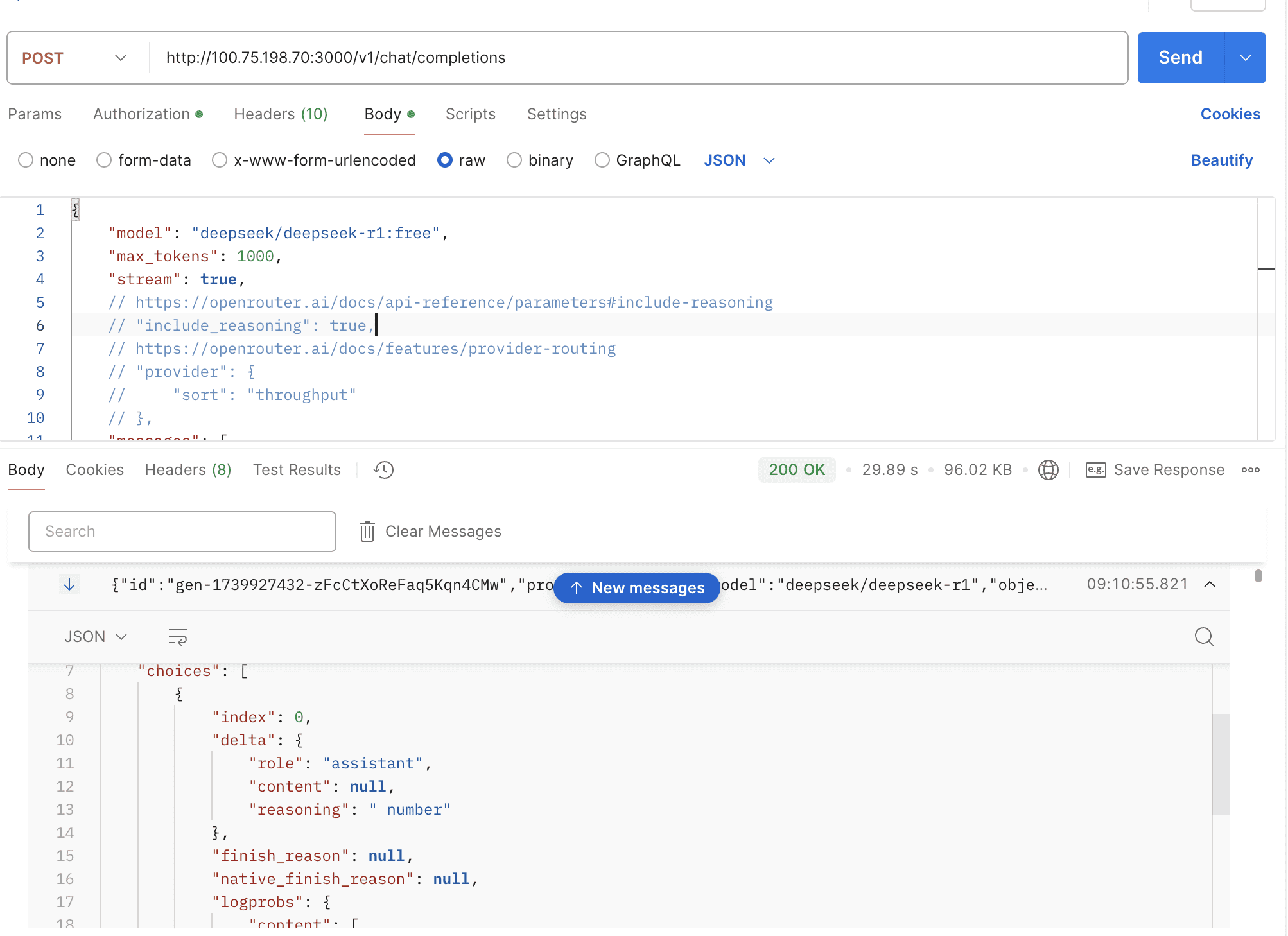
Support OpenRouter's reasoning content
By default, the thinking mode is automatically enabled for the deepseek-r1 model, and the response is returned in the open-router format.
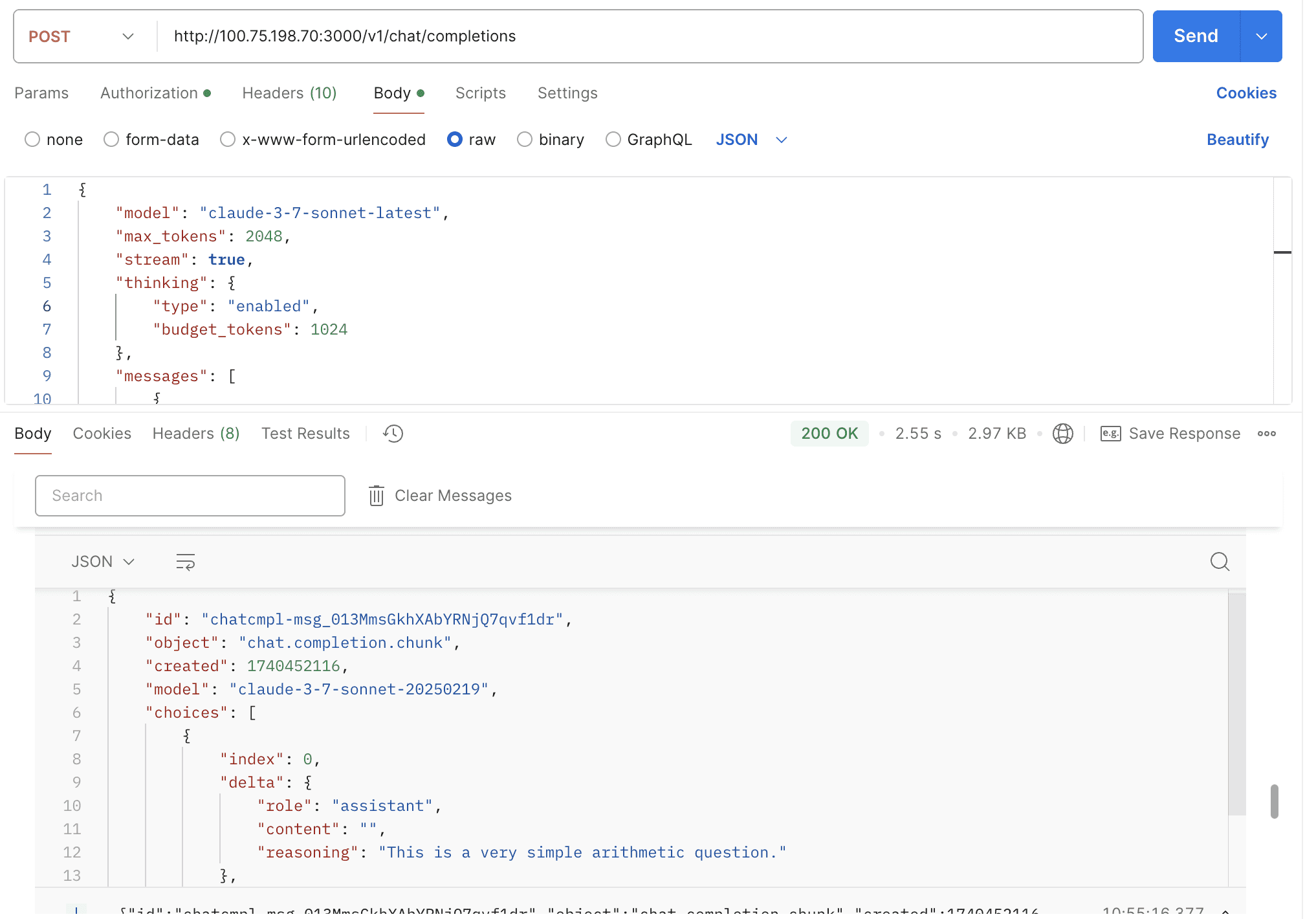
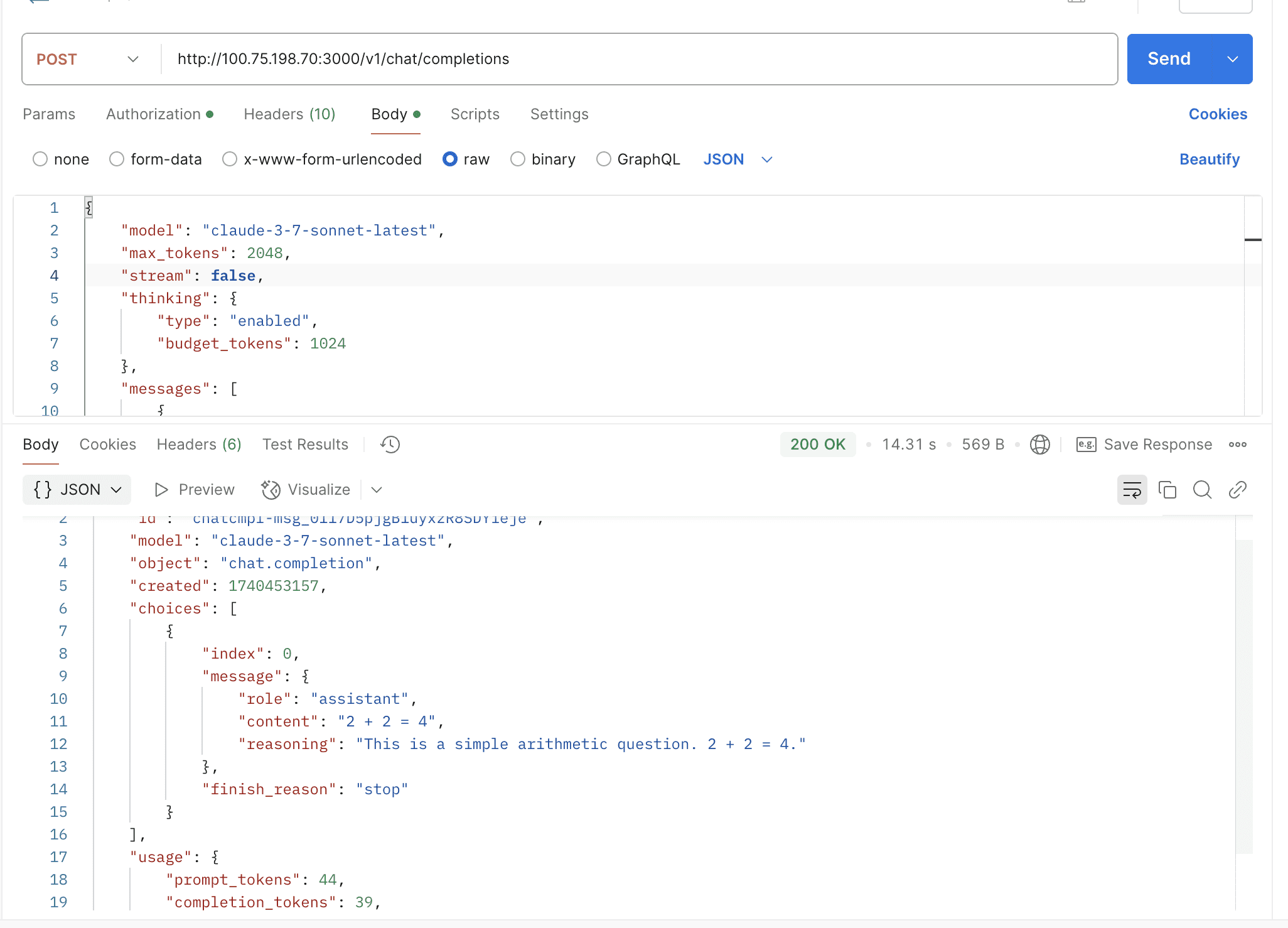
Support claude-3-7-sonnet & thinking
By default, the thinking mode is not enabled. You need to manually pass the thinking field in the request body to enable it.
Stream
Non-Stream
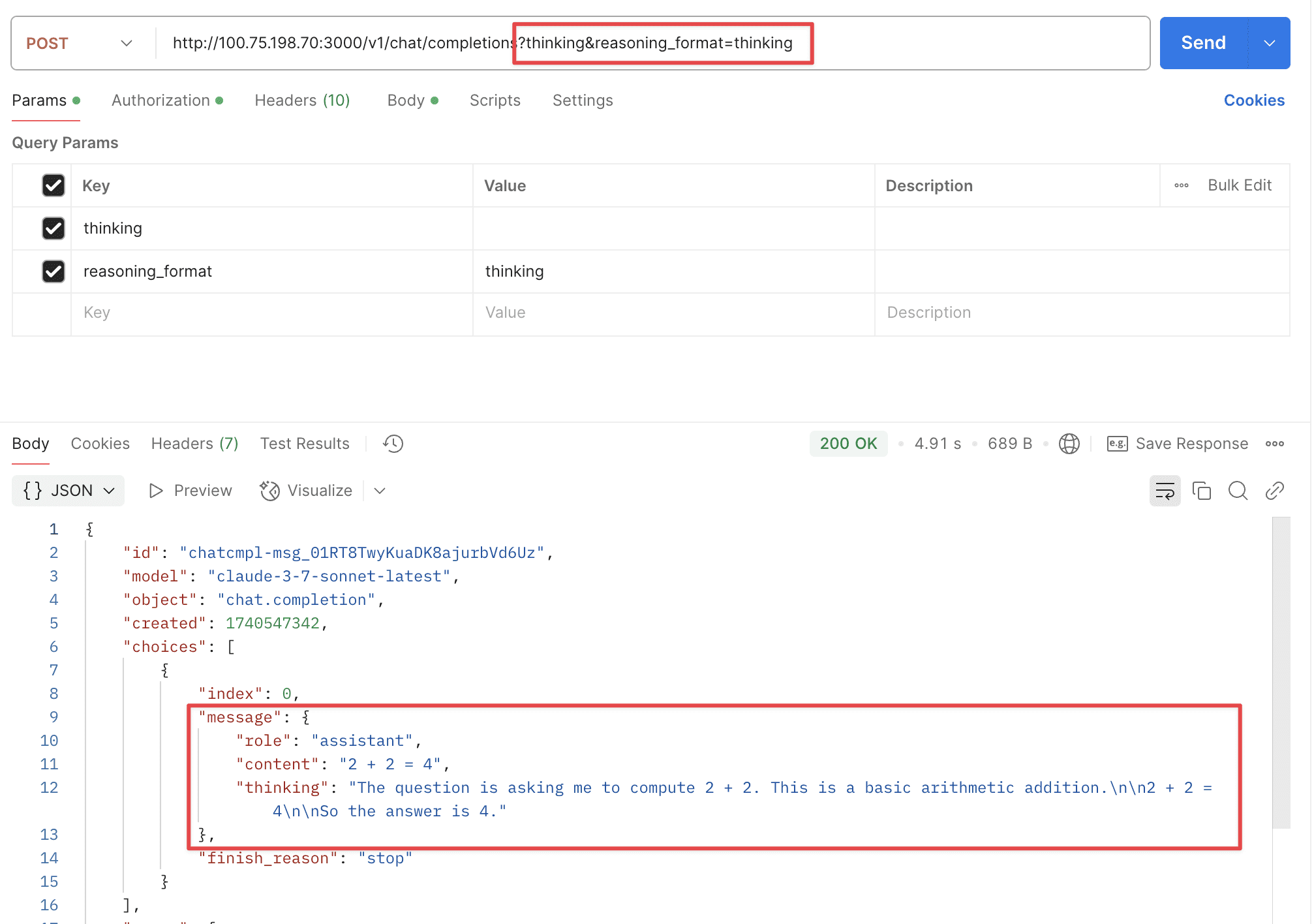
Automatically Enable Thinking and Customize Reasoning Format via URL Parameters
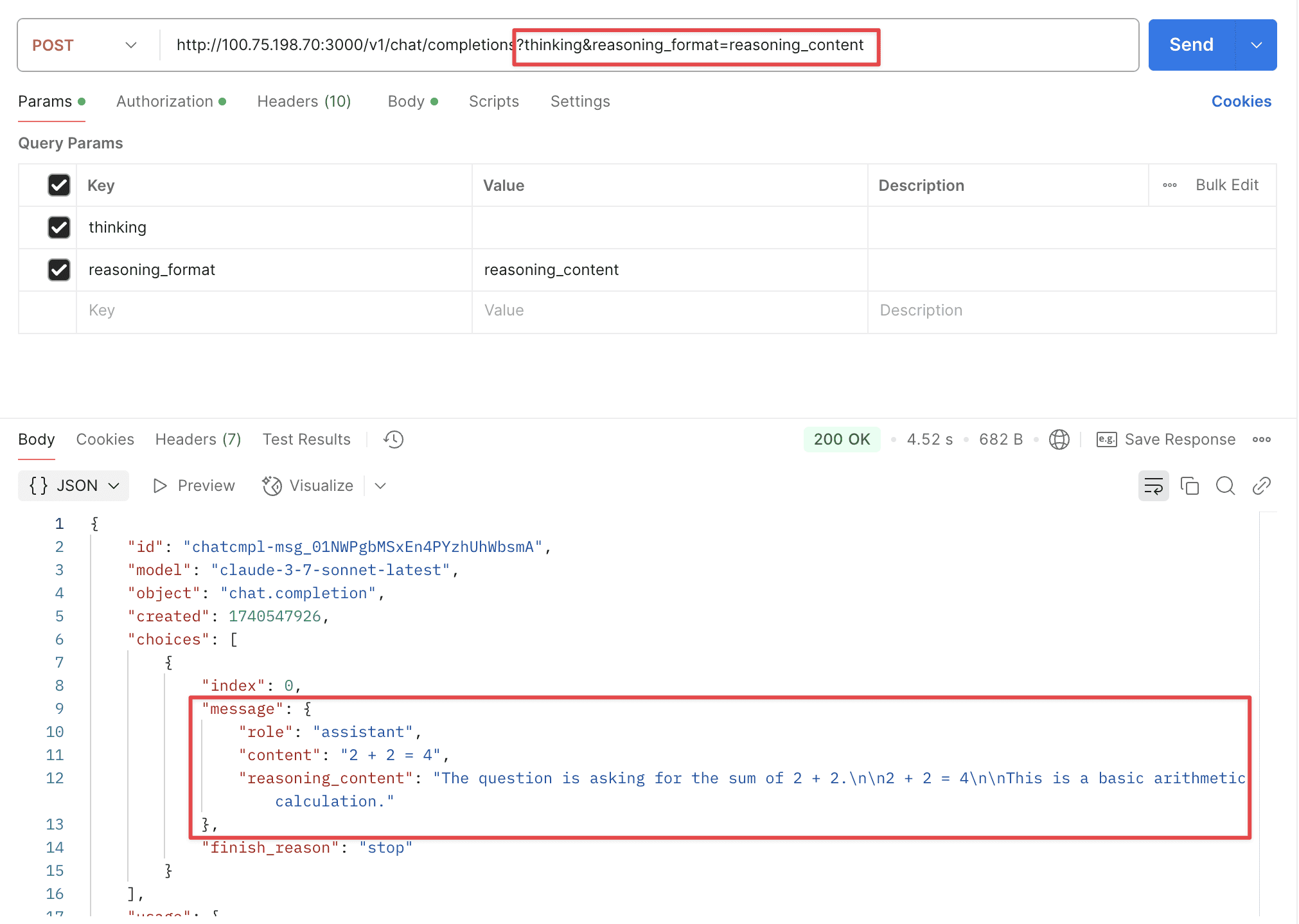
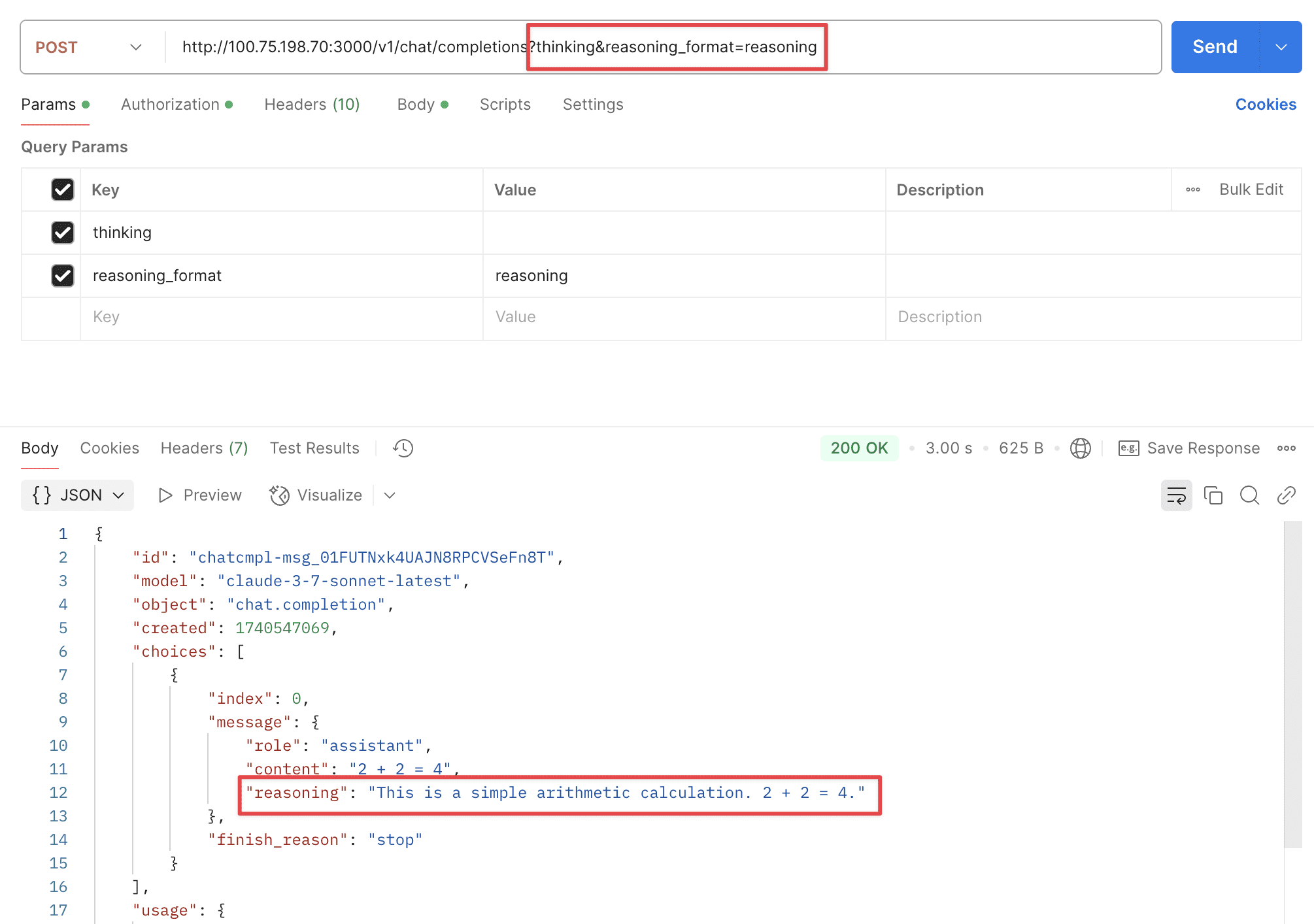
Supports two URL parameters: thinking and reasoning_format.
thinking: Whether to enable thinking mode, disabled by default.reasoning_format: Specifies the format of the returned reasoning.reasoning_content: DeepSeek official API format, returned in thereasoning_contentfield.reasoning: OpenRouter format, returned in thereasoningfield.thinking: Claude format, returned in thethinkingfield.
Reasoning Format - reasoning-content
Reasoning Format - reasoning
Reasoning Format - thinking
Bug fix
- BUGFIX: 更新令牌时的一些问题 #1933
- feat(audio): count whisper-1 quota by audio duration #2022
- fix: 修复高并发下,高额度用户使用低额度令牌没有预扣费而导致令牌大额欠费 #25
- fix: channel test false negative #2065
- fix: resolve "bufio.Scanner: token too long" error by increasing buff… #2128
- feat: Enhance VolcEngine channel support with bot model #2131
- fix: models api return models in deactivate channels #2150