16 KiB
截止到今天,我们已经将数据分析基础篇的内容都学习完了。在这个过程中,感谢大家积极踊跃地进行留言,既给其他同学提供了不少帮助,也让专栏增色了不少。在这些留言中,有很多同学对某个知识点有所疑惑,我总结了NumPy、Pandas、爬虫以及数据变换中同学们遇到的问题,精选了几个具有代表性的来作为答疑。
NumPy相关
答疑1:如何理解NumPy中axis的使用?
这里我引用文稿中的一段代码:
a = np.array([[4,3,2],[2,4,1]])
print np.sort(a)
print np.sort(a, axis=None)
print np.sort(a, axis=0)
print np.sort(a, axis=1)
同学们最容易混淆的是axis=0 和 axis=1的顺序。你可以记住:axis=0代表跨行(实际上就是按列),axis=1 代表跨列(实际上就是按行)。
如果排序的时候,没有指定axis,默认axis=-1,代表就是按照数组最后一个轴来排序。如果axis=None,代表以扁平化的方式作为一个向量进行排序。
所以上面的运行结果为:
[[2 3 4]
[1 2 4]]
[1 2 2 3 4 4]
[[2 3 1]
[4 4 2]]
[[2 3 4]
[1 2 4]]
我解释下axis=0的排序结果,axis=0代表的是跨行(跨行就是按照列),所以实际上是对[4, 2] [3, 4] [2, 1]来进行排序,排序结果是[2, 4] [3, 4] [1, 2],对应的是每一列的排序结果。还原到矩阵中也就是 2 3 1], [4, 4, 2。
答疑2:定义结构数组中的S32代表什么意思?
我文稿中定义了一个结构数组persontype。
import numpy as np
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['S32','i', 'i', 'i', 'f']})
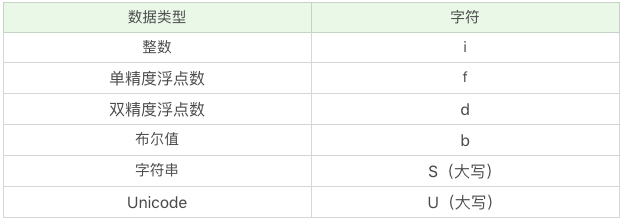
这里实际上用的是numpy中的字符编码来表示数据类型的定义,比如i代表整数,f代表单精度浮点数,S代表字符串,S32代表的是32个字符的字符串。
如果数据中使用了中文,可以把类型设置为U32,比如:
import numpy as np
persontype = np.dtype({
'names':['name', 'age', 'chinese', 'math', 'english'],
'formats':['U32','i', 'i', 'i', 'f']})
peoples = np.array([("张飞",32,75,100, 90),("关羽",24,85,96,88.5), ("赵云",28,85,92,96.5),("黄忠",29,65,85,100)], dtype=persontype)
答疑3:PyCharm中无法import numpy的问题
有些同学已经安装好了numpy,但在PyCharm中依然无法使用numpy。遇到这个问题的主要原因是PyCharm会给每一个新建的项目都是一个全新的虚拟环境。
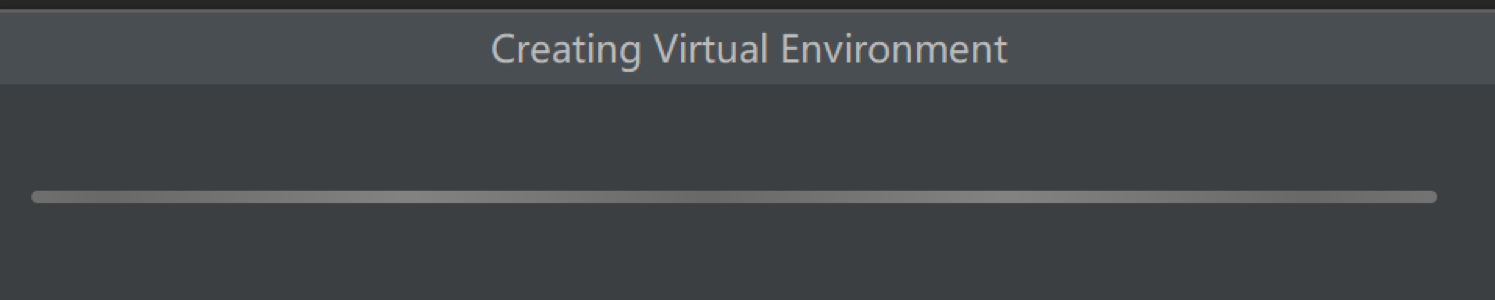
在这个环境下,默认的包只有pip、setuptools和wheel这三个工具,你可以在File->Settings里面找到这个界面。
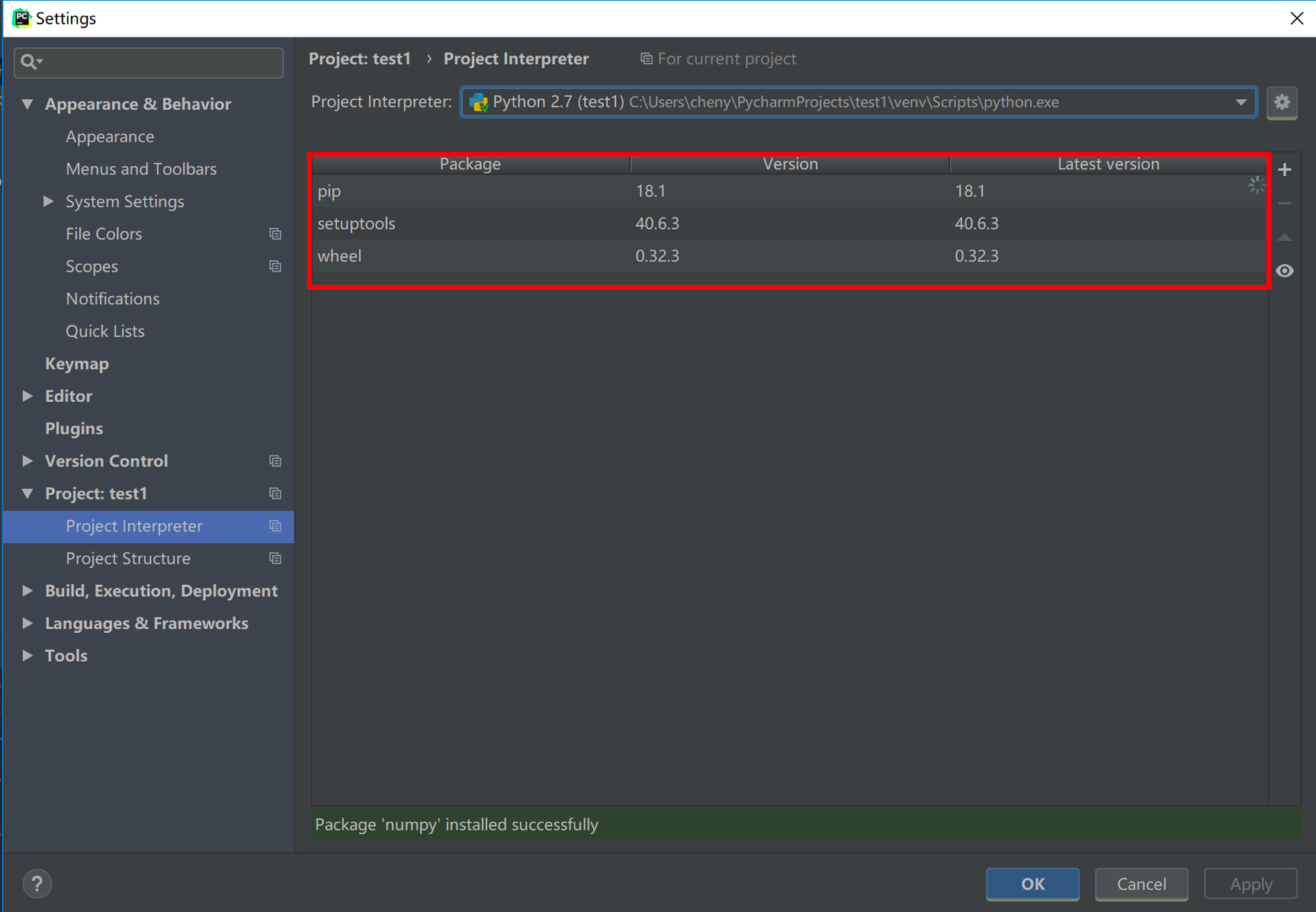
这说明numpy并没有配置到你创建的这个Project下的环境中,需要手动点击右侧的+号,对numpy进行添加。
添加之后,你就可以正常运行程序,显示出结果了。
答疑4:我不明白为什么打印出来的name会带一个b?
这位同学的代码是这样的:
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
print(a['name'])
结果:
[(b'abc', 21, 50.) (b'xyz', 18, 75.)]
[b'abc' b'xyz']
我来解释一下。Python3 默认str是Unicode类型,所以要转成bytestring,会在原来的str前加上b。如果你用py2.7就不会有这个问题,py3的b只是告诉你这里它转化成了bytestring进行输出。
答疑5:np.ceil代表什么意思?
ceil是numpy中的一个函数,代表向上取整。比如np.ceil(2.4)=3。
数据分析思维培养及练习相关
答疑1:Online Judge的比赛题目,数学不好怎么办?
Vol1~Vol32的难度是逐渐增加吗的,怎么可以选出有易到难的题目?
Online Judge有一些简单的题目可以选择,选择使用人数多,且accepted比例高的题目。另外它面向的是一些参加比赛的人员,比如高中的NOI比赛,或者大学的ACM比赛。你也可以选择leetcode或者pythontip进行训练。
难度不一定是增加的,而是出题的先后顺序。难易程度,你可以看下提交的人数和Accepted的比例。提交人数和Accepted比例越高,说明越简单。
答疑2:加餐中小区宽带使用多台手机等设备,不会被检测到吗?
小区宽带和手机飞行是两种解决方案。用手机飞行不需要用到小区宽带。 用小区宽带需要使用到交换机,这里可以自己来控制交换机,每次自动切换IP。
答疑3:加餐中提到的一万个手机号。。。那怎么更换呢?也要一万台设备吗?
1万个手机号,主要用于账号注册,通常采用的是“卡池”这个设备。简单来说,卡池可以帮你做收发短信。一个卡池设备512张卡,并发32路。
有了卡池,还需要算法。你不能让这512张卡每次操作都是有规律可循的,比如都是同步执行某项操作,否则微信、Facebook会直接把它们干掉。学过数据挖掘的人应该会知道,这512张卡如果是协同操作,可以直接被算法识别出来。在微信、Facebook看来,这512张卡实际上是同一个人,也就是“机器人”。所以卡池可以帮你做短信验证码,以便账号登录用。MIFI+SIM帮你做手机流量上网用。这是两套不同的设备。
答疑4:听说企业里用SQL和Excel进行数据分析的很多,这块该如何选择?
SQL和Excel做统计的工作多一些,涉及到编程的很少。如果你想在这个行业进一步提升,或者做一名算法工程师,那么你都要和Python打交道。专栏里数据挖掘算法的部分,是用Python交付的。Excel和SQL很难做数据挖掘。
如果想对数据概况有个了解,做一些基础分析,用Excel和SQL是OK的。但是想进一步挖掘数据的价值,掌握Python还是挺有必要的。
另外,如果你做的是数据可视化工作,在企业里会用到tableau或者powerBI这些工具。数据采集你也可以选择第三方工具,或者自己用Python来编写。
答疑5:学一些算法的时候比如SVM,是不是掌握它们的理论内容即可。不需要自己去实现,用的时候调用库即可?
是的,这些算法都有封装,直接使用即可。在python的sklearn中就是一行语句的事。
答疑6:老师,我现在等于从零开始学数据挖掘,所谓的数学基础指的是把高数学到哪种境界啊?是像考研那样不管极限导数积分每种题型都要会解,还是只需要了解这些必备的高数基础的概念?
不需要求解每一道数学题,只需要具备高数基础概念即可!概率论与数理统计、线性代数、最优化方法和图论这些,我在算法中涉及的地方都会讲到,你暂时不用提前学习这些数学知识。我觉得最好的方式就是在案例中灵活运用,这样可以加深你对这些数学知识的理解。
对于大部分从0开始学数据挖掘的人来说,可以淡化公式,重点理解使用场景和概念。
爬虫相关问题
答疑1:关于Python爬虫工具的推荐
我除了在专栏里讲到了Requests、XPath解析,以及Selenium、PhantomJS。还有一些工具是值得推荐的。
Scrapy是一个Python的爬虫框架,它依赖的工具比较多,所以在pip install的时候,会安装多个工具包。scrapy本身包括了爬取、处理、存储等工具。在scrapy中,有一些组件是提供给你的,需要你针对具体任务进行编写。比如在item.py对抓取的内容进行定义,在spider.py中编写爬虫,在pipeline.py中对抓取的内容进行存储,可以保存为csv等格式。这里不具体讲解scrapy的使用。
另外,Puppeteer是个很好的选择,可以控制Headless Chrome,这样就不用Selenium和PhantomJS。与Selenium相比,Puppeteer直接调用Chrome的API接口,不需要打开浏览器,直接在V8引擎中处理,同时这个组件是由Google的Chrome团队维护的,所以兼容性会很好。
答疑2:driver = webdriver.Chrome(),为什么输入这个代码就会报错了呢?
报错的原因是没有下载或正确配置ChromeDriver路径,正确的方法如下:
1.下载ChromeDriver,并放到Chrome浏览器目录中;
下载地址:http://npm.taobao.org/mirrors/chromedriver/72.0.3626.7/
2.将Chrome浏览器目录添加到系统的环境变量Path中,然后再运行下试试.
另外你也可以在代码中设置ChromeDriver的路径,方法如下:
chrome_driver = "C:\Users\cheny\AppData\Local\Google\Chrome\Application\chromedriver.exe"
driver = webdriver.Chrome(executable_path=chrome_driver)
答疑3:如果是需要用户登陆后才能爬取的数据该怎么用python来实现呢?
你可以使用Python+Selenium的方式完成账户的自动登录,因为Selenium是个自动化测试的框架,使用Selenium的webdriver就可以模拟浏览器的行为。找到输入用户名密码的地方,输入相应的值,然后模拟点击即可完成登录(没有验证码的情况下)。
另外你也可以使用cookie来登录网站,方法是你登录网站时,先保存网站的cookie,然后在下次访问的时候,加载之前保存的cookie,放到request headers中,这样就不需要再登录网站了。
答疑4:为什么我在豆瓣网查询图片的网址与你不一样?https://www.douban.com/search?cat=1025&q=王祖贤&source=suggest 。
咱们访问豆瓣查询图片的网址应该是一样的。只是我给出的是json的链接。
方法是这样的:用Chrome浏览器的开发者工具,可以监测出来网页中是否有json数据的传输,所以我给出的链接是json数据传输的链接: https://www.douban.com/j/search_photo?q=%E7%8E%8B%E7%A5%96%E8%B4%A4&limit=20&start=0
答疑5:XHR数据这个是如何查出来的,我使用chrome的开发者工具查看XHR数据,但是查不到这部分,麻烦老师帮忙解答。
你需要使用浏览器的插件查看 XHR 数据,比如在 Chrome的开发者工具。
在豆瓣搜索中,我们对“王祖贤”进行了模拟,发现 XHR 数据中有一个请求是这样的:
https://www.douban.com/j/search_photo?q=王祖贤&limit=20&start=0
你可以看一下操作流程。
数据变换相关
答疑1:数据规范化、归一化、标准化是同一个概念么?
数据规范化是更大的概念,它指的是将不同渠道的数据,都按照同一种尺度来进行度量,这样做有两个好处,一是让数据之间具有可比较性;另一个好处就是方便后续运算,因为数据在同一个数量级上规整了,在机器学习迭代的时候,也会加快收敛效率。
数据归一化和数据标准化都是数据规范化的方式。不同点在于数据归一化会让数据在一个[0,1]或者[-1,1]的区间范围内。而数据标准化会让规范化的数据呈现正态分布的情况,所以你可以这么记:归一化的“一”,是让数据在[0,1]的范围内。而标准化,目标是让数据呈现标准的正态分布。
答疑2:什么时候会用到数据规范化(Min-max、Z-Score和小数定标)?
刚才提到了,进行数据规范化有两个作用:一是让数据之间具有可比较性,二是加快后续算法的迭代收敛速度。
实际上你能看到Min-max、Z-Score和小数定标规范化都是一种线性映射的关系,将原来的数值投射到新的空间中。这样变换的好处就是可以看到在特定空间内的数值分布情况,比如通过Min-max可以看到数据在[0,1]之间的分布情况,Z-Score可以看到数值的正态分布情况等。
不论是采用哪种数据规范化方法,规范化后的数值都会在同一个数量的级别上,这样方便后续进行运算。
那么回过头来看,在数据挖掘算法中,是否都需要进行数据规范化呢?一般情况下是需要的,尤其是针对距离相关的运算,比如在K-Means、KNN以及聚类算法中,我们需要有对距离的定义,所以在做这些算法前,需要对数据进行规范化。
另外还有一些算法用到了梯度下降作为优化器,这是为了提高迭代收敛的效率,也就是提升找到目标函数最优解的效率。我们也需要进行数据规范化,比如逻辑回归、SVM和神经网络算法。
在这些算法中都有目标函数,需要对目标函数进行求解。梯度下降的目标是寻找到目标函数的最优解,而梯度的方法则指明了最优解的方向,如下图所示。
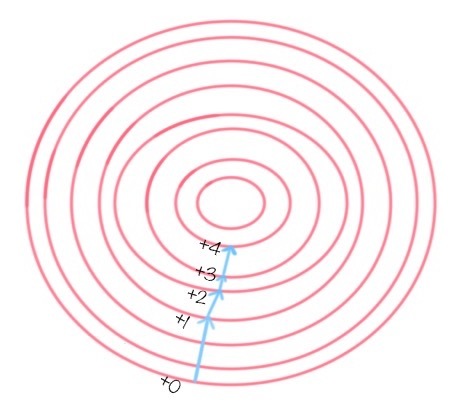
当然不是所有的算法都需要进行数据规范化。在构造决策树的时候,可以不用提前做数据规范化,因为我们不需要关心特征值的大小维度,也没有使用到梯度下降来做优化,所以数据规范化对决策树的构造结果和构造效率影响不大。除此之外,还是建议你在做数据挖掘算法前进行数据规范化。
答疑3:如何使用Z-Score规范化,将分数变成正态分布?
我在专栏文稿中举了一个Z-Score分数规范化的例子,假设A与B的考试成绩都为80分,A的考卷满分是100分(及格60分),B的考卷满分是500分(及格300分)。这里假设A和B的考试成绩都是成正态分布,可以直接采用Z-Score的线性化规范化方法。
在专栏的讨论区中,有个同学提出了“Z-Score”的非线性计算方式,大家可以一起了解下:
因为在很多情况下,数值如果不是正态分布,而是偏态分布,直接使用Z-Score的线性计算方式无法将分数转化成正态分布。采用以上的方法可以解决这一个问题,大家可以了解下。这里偏态分布指的是非对称分布的偏斜状态,包括了负偏态,也就是左偏态分布,以及正偏态,也就是右偏态分布。
我发现大家对工具的使用和场景比较感兴趣,所以最后留两道思考题。
第一道题:假设矩阵a = np.array(4,3,2],[2,4,1),请你编写代码将矩阵中的每一列按照从小到大的方式进行排序。
第二道题:你都用过哪些Python爬虫工具,抓取过哪些数据,觉得哪个工具好用?
欢迎你在评论分享你的想法,也欢迎你点击“请朋友读”,把它分享给你的朋友或者同事。